| ISO 9000 | ISO 14000 |
GMP Consulting |
Chapter 6: Authentication & AuthorizationIn previous chapters we've seen how to create dynamic pages, to interact with the remote user, and to maintain state across sessions. We haven't worried much about issues of user authorization: the Web server and all its modules were assumed to be accessable by all.In the real world, however, access to the Web server is not always unrestricted. The module you're working on may provide access to a database of proprietary information, may tunnel through a firewall system, or may control a hardware device that can be damaged if used improperly. Under circumstances like these you'll need to take care that the module can only be run by authorized users. In this chapter, we step back to an earlier phase of the HTTP transaction, one in which Apache attempts to determine the identity of the person at the other end of the connection, and whether he or she is authorized to access the resource. Apache's APIs for authentication and authorization are straightforward yet powerful. You can implement simple password-based checking in just a few lines of code. With somewhat more effort, you can implement more sophisticated authentication systems, such as ones based on hardware tokens.
Access Control, Authentication and AuthorizationWhen a remote user comes knocking at Apache's door to request a document, Apache acts like the bouncer standing at the entrance to a bar. It asks three questions:
How Access Control WorksAccess control is any type of restriction that doesn't require you to determine the identity of the remote user. Common examples of access control are those based on the IP address of the remote user's computer, on the time of day of the request, or those based on certain attributes of the requested document (for example, the remote user tries to fetch a directory listing when automatic directory indexing has been disabled).
Access control uses the HTTP
% telnet www.modperl.com 80 Connected to www.modperl.com. Escape character is '^]'. GET /articles/ HTTP/1.0
HTTP/1.1 403 Forbidden Date: Mon, 10 Nov 1998 12:43:08 GMT Server: Apache/1.3.3 mod_perl/1.16 Connection: close Content-Type: text/html
<HTML><HEAD> <TITLE>403 Forbidden</TITLE> </HEAD><BODY> <H1>Forbidden</H1> You don't have permission to access /articles/ on this server.<P> </BODY></HTML> Connection closed by foreign host. In this example, after connecting to the Web server's port, we typed in a GET request to fetch the URL /articles. However, access to this URL has been turned off at the server side using the following configuration file directives:
<Location /articles> deny from all </Location> Because access is denied to everyone, the server returns an HTTP header indicating the 403 status code. This is followed by a short explanatory HTML message for the browser to display. Since there's nothing more that the user can do to gain access to this URL, the browser displays this message and takes no further action. Apache's standard modules allow you to restrict access to a file or directory by the IP address or domain name of the remote host. By writing your own access control handler, you can take complete control of this process to grant or deny access based on any arbitrary criteria you choose. The examples given later in this chapter show you how to limit access based on the day of the week and by the user agent, but you can base the check on anything that doesn't require user interaction. For example, you might insist that the remote host has a reverse domain name system mapping, or limit access to hosts that make too many requests over a short period of time.
How Authentication and Authorization WorkIn contrast to access control, the process of authenticating a remote user is more involved. The question ``Is the user who they say they are?'' sounds simple, but the steps for verifying the answer can be simple or complex, depending on the level of assurance you desire. The HTTP protocol does not provide a way to answer the question of authenticity, only a method of asking it. It's up to the Web server itself to decide when a user is or is not authenticated.When a Web server needs to know who a user is, it issues a challenge using the HTTP 401 ``Authorization Required'' code (Figure 6.1). In addition to this code, the HTTP header includes one or more fields called WWW-Authenticate, indicating the type (or types) of authentication that the server considers acceptable. WWW-Authenticate may also provide other information, such as a challenge string to use in cryptographic authentication protocols. When a client sees the 401 response code it studies the WWW-Authenticate header and fetches the requested authentication information if it can. If need be, the client requests some information from the user, such as prompting for an account name and password, or requiring the user to insert a smart token containing a cryptographic signature. Armed with this information, the browser now issues a second request for the URL, but this time adding an Authorization field containing the information necessary to establish the user's credentials. (Notice that this field is misnamed since it provides authentication information, not authorization information.) The server checks the contents of Authorization, and if it passes muster the request is passed on to the authorization phase of the transaction, where the server will decide whether the authenticated user has access to the requested URL. On subsequent requests to this URL, the browser remembers the user's authentication information and automatically provides it in the Authorization field. This way the user doesn't have to provide his credentials each time he fetches a page. The browser also provides the same information for URLs at the same level or beneath the current one, anticipating the common situation in which an entire directory tree is placed under access control. If the authentication information becomes invalid (for example, in a scheme in which authentication expires after a period of time), the server can again issue a 401 response, forcing the browser to request the user's credentials all over again. The contents of WWW-Authenticate and Authorization are specific to the particular authentication scheme. Fortunately only three authentication schemes are in general use, and just one dominates the current generation of browsers and servers*. This is the Basic authentication scheme, the first authentication scheme defined in the HTTP protocol. Basic authentication is, well, basic! It is the standard account name/password scheme that we all know and love.
% telnet www.modperl.com 80 Connected to www.modperl.com. Escape character is '^]'. GET /private/ HTTP/1.0
HTTP/1.1 401 Authorization Required Date: Mon, 10 Nov 1998 1:01:17 GMT Server: Apache/1.3.3 mod_perl/1.16 WWW-Authenticate: Basic realm="Test" Connection: close Content-Type: text/html
<HTML><HEAD> <TITLE>Authorization Required</TITLE> </HEAD><BODY> <H1>Authorization Required</H1> This server could not verify that you are authorized to access the document you requested. Either you supplied the wrong credentials (e.g., bad password), or your browser doesn't understand how to supply the credentials required.<P> </BODY></HTML> Connection closed by foreign host. In this example, we requested the URL /private/, which has been placed under Basic authentication. The returned HTTP 401 status code indicates that some sort of authentication is required, and the WWW-Authenticate field tells the browser to use Basic authentication. The WWW-Authenticate field also contains scheme-specific information following the name of the scheme. In the case of Basic authentication, this information consists of the authorization ``realm'' and a string for the browser to display in the password dialog box. One purpose of this information is to hint to the user which password he should provide on systems that maintain more than one set of accounts. Another purpose is to allow the browser to automatically provide the same authentication information if it later encounters a discontiguous part of the site that uses the same realm name. However, the authors have found not all browsers implement this feature. Following the HTTP header is some HTML for the browser to display. Unlike the situation with the 403 status, however, the browser doesn't immediately display this page. Instead it pops up a dialog box to request the user's account name and password. The HTML is only displayed if the user presses ``Cancel'', or in the rare case of browsers that don't understand Basic authentication. After the user enters his credentials, the browser attempts to fetch the URL once again, this time providing the credential information in the Authorization field. The request (which you can try yourself) will look something like this:
% telnet www.modperl.com 80 Connected to www.modperl.com. Escape character is '^]'. GET /private/ HTTP/1.0 Authorization: Basic Z2FuZGFsZjp0aGUtd2l6YXJk
HTTP/1.1 200 OK Date: Mon, 10 Nov 1998 1:43:56 GMT Server: Apache/1.3.3 mod_perl/1.16 Last-Modified: Thu, 29 Jan 1998 11:44:21 GMT ETag: "1612a-18-34d06b95" Content-Length: 24 Accept-Ranges: bytes Connection: close Content-Type: text/plain
Hi there.
How are you? Connection closed by foreign host. The contents of the Authorization field are the security scheme, ``Basic'' in this case, and scheme-specific information. For Basic authentication, this consists of the user's name and password, concatenated together and encoded with base64. Although the example makes it look like the password is encrypted in some clever way, it's not, a fact that you can readily prove to yourself if you have the MIME::Base64 module installed.*
% perl -MMIME::Base64 -le 'print decode_base64 "Z2FuZGFsZjp0aGUtd2l6YXJk" gandalf:the-wizard
After successfully authenticating a user, Apache enters its authorization phase. Just because a user can prove that he is who he claims to be doesn't mean he has unrestricted access to the site! During this phase Apache applies any number of arbitrary tests to the authenticated username. Apache's default handlers allow you to grant access to users based on their account names or their membership in named groups, using a variety of flat file and hashed lookup table formats. By writing custom authorization handlers, you can do much more than this. You can perform a SQL query on an enterprise database, consult the company's current organizational chart to implement role-based authorization, or apply ad hoc rules like allowing users named ``Fred'' access on alternate Tuesdays. Or how about something completely different from the usual Web access model, such as a system in which the user purchases a certain number of ``pay per view'' accesses in advance? Each time he accesses a page, the system decrements a counter in a database. When the user's access count hits zero, the server denies him access.
Access Control with mod_perlThis section will show you how to write a simple access control handler in mod_perl.
A Simple Access Control ModuleTo create an access control module, you'll install a handler for the access control phase by adding a PerlAccessHandler directive to one of Apache's configuration files or to a per-directory .htaccess file. The access control handler has the job of giving thumbs up or down for each attempted access to the URL. The handler indicates its decision in the result code it returns to the server. OK will allow the user in,FORBIDDEN will forbid access by issuing a 403 status code, and DECLINED will defer the decision to any other access control handlers that may be
installed.
We begin with the simplest type of access control, a stern module called Apache::GateKeeper (listing 6.1). Apache::GateKeeper recognizes a single configuration variable named Gate. If the value of Gate is ``open'', the module allows access to the URL under its control. If the value of Gate is ``closed'', the module forbids access. Any other value results in a ``internal server error'' message. The code is straightforward. It begins in the usual way by importing the common Apache and HTTP constants from Apache::Constants:
package Apache::GateKeeper; # file: Apache/GateKeeper.pm use strict; use Apache::Constants qw(:common);
sub handler {
my $r = shift;
my $gate = $r->dir_config("Gate");
return DECLINED unless defined $gate;
return OK if lc($gate) eq 'open';
When the handler is executed, it fetches the value of the Gate variable. If the variable is absent, the handler declines to handle the transaction, deferring the decision to other handlers that may be installed. If the variable is present, the handler checks its value, and returns a value of OK if Gate is ``open''.
if (lc $gate eq 'closed') {
$r->log_reason("Access forbidden unless the gate is open", $r->filename);
return FORBIDDEN;
}
$r->log_error($r->uri, ": Invalid value for Gate ($gate)");
return SERVER_ERROR;
}
On the other hand, if the value of Gate is ``closed'' the handler returns a
package Apache::GateKeeper;
# file: Apache/GateKeeper.pm
use strict;
use Apache::Constants qw(:common);
sub handler {
my $r = shift;
my $gate = $r->dir_config("Gate");
return DECLINED unless defined $gate;
return OK if lc $gate eq 'open';
if (lc $gate eq 'closed') {
$r->log_reason("Access forbidden unless the gate is open", $r->filename);
return FORBIDDEN;
}
$r->log_error($r->uri, ": Invalid value for Gate ($gate)");
return SERVER_ERROR;
}
1;
__END__
PerlAccessHandler Apache::GateKeeper PerlSetVar Gate closed The bottom of the listing shows the two-line .htaccess entry required to turn on Apache::GateKeeper for a particular directory (you could also use a <Location> or <Directory> entry for this purpose). It uses the PerlAccessHandler directive to install Apache::GateKeeper as the access handler for this directory, then calls PerlSetVar to set the Perl configuration variable Gate to ``closed.'' How does the GateKeeper access control handler interact with other aspects of Apache access control, authentication and authorization? If an authentication handler is also installed, for example by including a ``require valid-user'' directive in the .htaccess file, then Apache::GateKeeper is called as only the first step in the process. If Apache::GateKeeper returns OK, then Apache will go on to the authentication phase and the user will be asked to provide his name and password. However, this behavior can be modified by placing the line Satisfy any in the .htaccess file or directory configuration section. When this directive is in effect, Apache will try access control first and then try authentication/authorization. If either returns OK, then the request will be satisfied. This lets certain privileged users get into the directory even when Gate is closed. (The bouncer steps aside when he recognizes his boss!) Now consider a .htaccess file like this one:
PerlAccessHandler Apache::GateKeeper PerlSetVar Gate open
order deny,allow deny from all allow from 192.168.2 This configuration installs two access control handlers, one implemented by the standard mod_access module (which also defines the order, allow and deny directives), and Apache::GateKeeper. The two handlers are potentially in conflict. The IP-based restrictions implemented by mod_access forbid access from any address but those in a privileged 192.168.2 subnet. Apache::GateKeeper, in contrast, is set to allow access to the subdirectory from anyone. Who wins?
The Apache server's method for resolving these situations is to call each
handler in turn in the reverse order of installation. If the handler
returns The Satisfy any directive has no effect on this situation.
Time-Based Access ControlFor a slightly more interesting access handler, consider Listing 6.2, which implements access control based on the day of the week. URLs protected by this handler will only be accessible on the days listed in a variable named ReqDay. This could be useful for a Web site that observes the sabbath, or, more plausibly, might form the basis for a generic module that implements time-based access control. Many sites perform routine maintenance at scheduled times of the day, and it's often helpful to keep visitors out of directories while they're being updated.
The handler, Apache::DayLimit, begins by fetching the ReqDay
configuration variable. If not present, it declines the transaction and
gives some other handler a chance to consider it. Otherwise, the handler
splits out the day names, which are assumed to be contained in a space- or
comma-delimited list, and compares them to the current day obtained from
the localtime() function. If there's a match, the handler allows the access by returning OK. Otherwise, it returns the
package Apache::DayLimit;
use strict;
use Apache::Constants qw(:common);
use Time::localtime;
my @wday = qw(sunday monday tuesday wednesday thursday friday saturday);
sub handler {
my $r = shift;
my $requires = $r->dir_config("ReqDay");
return DECLINED unless $requires;
my $day = $wday[localtime->wday];
return OK if $requires =~ /$day([,\s]+|$)/i;
$r->log_reason(qq{Access forbidden on weekday "$day"}, $r->uri);
return FORBIDDEN;
}
1;
__END__
<Location /weekends_only> PerlSetVar ReqDay saturday,sunday PerlAccessHandler Apache::DayLimit </Location>
Browser-Based Access ControlWeb-crawling robots are an increasing problem for Webmasters. Robots are supposed to abide by an informal agreement known as the robot exclusion standard (RES), in which the robot checks a file named robots.txt that tells it what parts of the site it is allowed to crawl through. Many rude robots, however, ignore the RES, or, worse, exploit robots.txt to guide them to the ``interesting'' parts. The next example (Listing 6.3) gives the outline of a robot exclusion module called Apache::BlockAgent. With it you can block the access of certain Web clients based on their User-Agent field (which frequently, although not invariably, identifies robots).The module is configured with a ``bad agents'' text file. This file contains a series of pattern matches, one per line. The incoming request's user agent field will be compared to each of these patterns in a case-insensitive manner. If any of the patterns hit, the request will be refused. Here's a small sample file that contains pattern matches for a few robots that have been reported to behave rudely: Sample bad agents file
^teleport pro\/1\.28 ^nicerspro ^mozilla\/3\.0 \(http engine\) ^netattache ^crescent internet toolpak http ole control v\.1\.0 ^go-ahead-got-it ^wget ^devsoft's http component v1\.0 ^www\.pl ^digout4uagent Rather than hard-code the location of the bad agents file, we set its path using a configuration variable named BlockAgentFile. An directory configuration section like this one will apply the Apache::BlockAgent handler to the entire site:
<Location /> PerlAccessHandler Apache::BlockAgent PerlSetVar BlockAgentFile conf/bad_agents.txt </Location> This is a long module, so we'll step through the code a section at a time.
package Apache::BlockAgent; use strict; use Apache::Constants qw(:common); use Apache::File (); use Apache::Log (); use Safe ();
my $Safe = Safe->new; my %MATCH_CACHE;
The module brings in the common Apache constants, and loads file-handling
code from Apache::File. It also brings in the
Apache::Log module, which makes the logging API available. The standard Safe module is pulled in next and a new compartment is created where code will
be compiled. We'll see later how the
sub handler {
my $r = shift;
my($patfile, $agent, $sub);
return DECLINED unless $patfile = $r->dir_config('BlockAgentFile');
return FORBIDDEN unless $agent = $r->header_in('User-Agent');
return SERVER_ERROR unless $sub = get_match_sub($r, $patfile);
return OK if $sub->($agent);
$r->log_reason("Access forbidden to agent $agent", $r->filename);
return FORBIDDEN;
}
The code first checks that the BlockAgentFile configuration variable is present. If not, it declines to handle the
transaction. It then attempts to fetch the User-Agent field from the HTTP header, by calling the request object's header_in() method. If no value is returned by this call (which might happen if a
sneaky robot declines to identify itself), we return
Otherwise, we call an internal function named get_match_sub() with the request object and the path to the bad agent file.
get_match_sub() uses the information contained within the file to compile an anonymous
subroutine which, when called with the user agent identification, returns a
true value if the client is OK, or false if it matches one of the forbidden
patterns. If get_match_sub()
returns an undefined value, it indicates that one or more of the patterns
didn't compile correctly and we return a server error. Otherwise we call
the returned subroutine with the agent name, and return OK or The remainder of the module is taken up by the definition of get_match_sub(). This subroutine is interesting because it illustrates the advantage of a persistent module over a transient CGI script:
sub get_match_sub {
my($r, $filename) = @_;
$filename = $r->server_root_relative($filename);
my $mtime = (stat $filename)[9];
# try to return the sub from cache
return $MATCH_CACHE{$filename}->{'sub'} if
$MATCH_CACHE{$filename} &&
$MATCH_CACHE{$filename}->{'mod'} >= $mtime;
Rather than tediously read in the bad agents file each time we're called,
compile each of the patterns, and test them, we compile the pattern match
tests into an anonymous subroutine and store it in the
Next we open up the bad agents file, fetch the patterns, and build up a subroutine line by line using a esries of string concatenations:
my($fh, @pats);
return undef unless $fh = Apache::File->new($filename);
chomp(@pats = <$fh>); # get the patterns into an array
my $code = "sub { local \$_ = shift;\n";
foreach (@pats) {
next if /^#/;
$code .= "return if /$_/i;\n";
}
$code .= "1; }\n";
$r->server->log->debug("compiled $filename into:\n $code");
Note the use of $r->server->log->debug() to send a debugging message to the server log file. This message will only
appear in the error log if the LogLevel is set to debug. If all goes well, the synthesized subroutine stored in
sub {
$_ = shift;
return if /^teleport pro\/1\.28/i;
return if /^nicerspro/i;
return if /^mozilla\/3\.0 \(http engine\)/i;
...
1;
}
After building up the subroutine we run a match-all regular expression over the code, untainting what was read from disk. In most cases, blindly untainting data is a bad idea, rendering the taint check mechansim useless. However, since we are using a Safe compartment and the reval() method, potentially dangerous operations such as system() are disabled and access to other namespaces is forbidden.
# create the sub, cache and return it
($code) = $code =~ /^(.*)$/s; #untaint
my $sub = $Safe->reval($code);
unless ($sub) {
$r->log_error($r->uri, ": ", $@);
return;
}
The untainting step is only required if taint checks are turned on with the PerlTaintCheck on directive (see Appendix A), and marks the code as safe to pass to eval() (in other words, it ``untaints'' it). We compile the code inside a Safe compartment, simply as an extra level caution. It would be OK to use the builtin eval() here because the same level of trust in the bad agents file should be just as any other Apache configuration file. The result of eval()ing the string is a CODE reference to an anonymous subroutine, or undef if something went wrong during the compilation. In the latter case, we log the error and return.
The final step is to store the compiled subroutine and the bad agent file's
modification time into
@{ $MATCH_CACHE{$filename} }{'sub','mod'} = ($sub, $mtime);
return $MATCH_CACHE{$filename}->{'sub'};
}
Because there may be several pattern files applicable to different parts of
the site, we key As we saw in Chapter 4, this technique of compiling and caching a dynamically-evaluated subroutine is a powerful optimization that allows Apache::BlockAgent to keep up with even very busy sites. Going one step further, Apache::BlockAgent module could avoid parsing the pattern file parsing entirely by defining its own custom configuration directives. The technique for doing this is described in Chapter 7.*
package Apache::BlockAgent;
use strict;
use Apache::Constants qw(:common);
use Apache::File ();
use Apache::Log ();
use Safe ();
my $Safe = Safe->new;
my %MATCH_CACHE;
sub handler {
my $r = shift;
my($patfile, $agent, $sub);
return DECLINED unless $patfile = $r->dir_config('BlockAgentFile');
return FORBIDDEN unless $agent = $r->header_in('User-Agent');
return SERVER_ERROR unless $sub = get_match_sub($r, $patfile);
return OK if $sub->($agent);
$r->log_reason("Access forbidden to agent $agent", $r->filename);
return FORBIDDEN;
}
# This routine creates a pattern matching subroutine from a
# list of pattern matches stored in a file.
sub get_match_sub {
my($r, $filename) = @_;
$filename = $r->server_root_relative($filename);
my $mtime = (stat $filename)[9];
# try to return the sub from cache
return $MATCH_CACHE{$filename}->{'sub'} if
$MATCH_CACHE{$filename} &&
$MATCH_CACHE{$filename}->{'mod'} >= $mtime;
# if we get here, then we need to create the sub
my($fh, @pats);
return unless $fh = Apache::File->new($filename);
chomp(@pats = <$fh>); # get the patterns into an array
my $code = "sub { local \$_ = shift;\n";
foreach (@pats) {
next if /^#/;
$code .= "return if /$_/i;\n";
}
$code .= "1; }\n";
$r->server->log->debug("compiled $filename into:\n $code");
# create the sub, cache and return it
($code) = $code =~ /^(.*)$/s; #untaint
my $sub = $Safe->reval($code);
unless ($sub) {
$r->log_error($r->uri, ": ", $@);
return;
}
@{ $MATCH_CACHE{$filename} }{'sub','mod'} = ($sub, $mtime);
return $MATCH_CACHE{$filename}->{'sub'};
}
1;
__END__
Blocking Greedy ClientsA limitation of using pattern matching to identify robots is that it only catches the robots that you know about, and only those that identify themselves by name. A few devious robots masquerade as users by using user agent strings that identify themselves as conventional browsers. To catch such robots, you'll have to be more sophisticated.A trick that some mod_perl developers have used to catch devious robots is to block access to things that act like robots by requesting URLs at a rate faster than even the twitchiest of humans can click a mouse. The strategy is to record the time of the initial access by the remote agent, and to count the number of requests it makes over a period of time. If it exceeds the speed limit, it gets locked out. Apache::SpeedLimit (listing 6.4) shows one way to write such a module. The module starts out much like the previous examples:
package Apache::SpeedLimit; use strict; use Apache::Constants qw(:common); use Apache::Log (); use IPC::Shareable (); use vars qw(%DB);
Because it needs to track the number of hits each client makes on the site, Apache::SpeedLimit faces the problem of maintaining a persistent variable across processes
that we have seen before. Here, because performance is an issue in a script
that will be called for every URL on the site, we solve the problem by
tieing a hash to shared memory using IPC::Shareable. The tied variable,
sub handler {
my $r = shift;
return DECLINED unless $r->is_main; # don't handle sub-requests
my $speed_limit = $r->dir_config('SpeedLimit') || 10; # Accesses per minute
my $samples = $r->dir_config('SpeedSamples') || 10; # Sampling threshold (hits)
my $forgive = $r->dir_config('SpeedForgive') || 20; # Forgive after this period
The handler() subroutine first fetches some configuration variables. The recognized directives include SpeedLimit, the number of accesses per minute that any client is allowed to make, SpeedSamples, the number of hits that the client must make before the module starts calculating statistics, and SpeedForgive, a ``statute of limitations'' on breaking the speed limit. If the client pauses for SpeedForgive minutes before trying again, the module will forgive it and treat the access as if it were the very first one. A small but important detail is the second line in the handler, where the subroutine declines the transaction unless is_main() returns true. It is possible for this handler to be invoked as the result of an internal subrequest, for example when Apache is rapidly iterating through the contents of an automatically-indexed directory to determine the MIME types of each of the directory's files. We do not want such subrequests to count against the user's speed limit totals, so we ignore any request that isn't the main one. is_main() returns true for the main request, false for subrequests. In addition to this, there's an even better reason for the is_main() check, because the very next thing the handler routine does is to call lookup_uri() to look up the requested file's content type and to ignore requests for image files. Without the check, the handler would recurse infinitely:
my $content_type = $r->lookup_uri($r->uri)->content_type; return OK if $content_type =~ m:^image/:i; # ignore images The rationale for the check for image files is that when a browser renders a graphics-intensive page, it generates a flurry of requests for in-line images that can easily exceed the speed limit. We don't want to penalize users for this, so we ignore requests for inline images. It's necessary to make a subrequest to fetch the requested file's MIME type because access control handlers ordinarily run before the MIME type checker phase.
If we are dealing with a non-image document, then it should be counted
against the client's total. In the next section of the module, we tie a
hash named
tie %DB, 'IPC::Shareable', 'SPLM', {create => 1, mode => 0644}
unless defined %DB;
my($ip, $agent) = ($r->connection->remote_ip, $r->header_in('User-Agent'));
my $id = "$ip:$agent";
my $now = time()/60; # minutes since the epoch
The client's IP address alone would be adequate in a world of one desktop PC per user, but the existence of multiuser systems, firewalls and Web proxies complicates the issue, making it possible for multiple users to appear to originate at the same IP address. This module's solution is to create an ID that consists of the IP address concatenated with the User-Agent field. As long as Microsoft and Netscape release new browsers every few weeks this combination will spread clients out sufficiently for this to be a practical solution. A more robust solution could make use of the optional cookie generated by Apache's mod_usertrack module, but we didn't want to complicate this example overly. A final preparatory task is to fetch the current time and scale it to minute units.
tied(%DB)->shlock;
my($first, $last, $hits, $locked) = split ' ', $DB{$id};
Now we update the user's statistics and calculate his current fetch speed. In preparation for working with the shared data we call the tied hash's shlock() method, locking the data structure for writing. Next, we look up the user's statistics and split it into individual fields.
At this point in the code we enter a block named
my $result = OK;
my $l = $r->server->log;
CASE:
{
Just before entering the block, we set a variable named
The first case we consider is when the
unless ($first) { # we're seeing this client for the first time
$l->debug("First request from $ip. Initializing speed counter.");
$first = $last = $now;
$hits = $locked = 0;
last CASE;
}
In this case, we can safely assume that this is the first time we're seeing this client. Our action is to initialize the fields and exit the block. The second case occurs when the interval between the client's current and last accesses are longer than the grace period:
if ($now - $last > $forgive) { # beyond the grace period. Treat like first
$l->debug("$ip beyond grace period. Reinitializing speed counter.");
$last = $first = $now;
$hits = $locked = 0;
last CASE;
}
In this case, we treat this access as a whole new session and reinitialize all the fields to their starting values. This ``forgives'' the client, even if it previously was locked out. At this point, we can bump up the number of hits and update the last access time. If the number of hits is too small to make decent statistics, we just exit the block at this point:
$last = $now; $hits++;
if ($hits < $samples) {
$l->debug("$ip not enough samples to calculate speed.");
last CASE;
}
Otherwise, if the user is already locked out, we set the result code to
if ($locked) { # already locked out, so forbid access
$l->debug("$ip locked");
$result = FORBIDDEN;
last CASE;
}
If the client isn't yet locked out , then we calculate its average fetch
speed by dividing the number of accesses it has made by the time interval
between now and its first access. If this value exceeds the speed limit, we
set the
my $interval = $now - $first;
$l->debug("$ip speed = ", $hits/$interval);
if ($hits/$interval > $speed_limit) {
$l->debug("$ip exceeded speed limit. Blocking.");
$locked = 1;
$result = FORBIDDEN;
last CASE;
}
}
At the end of the module, we check the result code. If it's
$r->log_reason("Client exceeded speed limit.", $r->filename)
if $result == FORBIDDEN;
$DB{$id} = join " ", $first, $now, $hits, $locked;
tied(%DB)->shunlock;
return $result;
}
To apply the Apache::SpeedLimit module to your entire site, you would create an configuration file entry like the following:
<Location /> PerlAccessHandler Apache::SpeedLimit PerlSetVar SpeedLimit 20 # max 20 accesses/minute PerlSetVar SpeedSamples 5 # 5 hits before doing statistics PerlSetVar SpeedForgive 30 # amnesty after 30 minutes </Location>
package Apache::SpeedLimit;
# file: Apache/SpeedLimit.pm
use strict;
use Apache::Constants qw(:common);
use Apache::Log ();
use IPC::Shareable ();
use vars qw(%DB);
sub handler {
my $r = shift;
return DECLINED unless $r->is_main; # don't handle sub-requests
my $speed_limit = $r->dir_config('SpeedLimit') || 10; # Accesses per minute
my $samples = $r->dir_config('SpeedSamples') || 10; # Sampling threshold (hits)
my $forgive = $r->dir_config('SpeedForgive') || 20; # Forgive after this period (minutes)
my $content_type = $r->lookup_uri($r->uri)->content_type;
return OK if $content_type =~ m:^image/:i; # ignore images
tie %DB, 'IPC::Shareable', 'SPLM', {create => 1, mode => 0644}
unless defined %DB;
my($ip, $agent) = ($r->connection->remote_ip, $r->header_in('User-Agent'));
my $id = "$ip:$agent";
my $now = time()/60; # minutes since the epoch
# lock the shared memory while we work with it
tied(%DB)->shlock;
my($first, $last, $hits, $locked) = split ' ', $DB{$id};
my $result = OK;
my $l = $r->server->log;
CASE:
{
unless ($first) { # we're seeing this client for the first time
$l->debug("First request from $ip. Initializing speed counter.");
$first = $last = $now;
$hits = $locked = 0;
last CASE;
}
if ($now - $last > $forgive) { # beyond the grace period. Treat like first
$l->debug("$ip beyond grace period. Reinitializing speed counter.");
$last = $first = $now;
$hits = $locked = 0;
last CASE;
}
# update the values now
$last = $now; $hits++;
if ($hits < $samples) {
$l->debug("$ip not enough samples to calculate speed.");
last CASE;
}
if ($locked) { # already locked out, so forbid access
$l->debug("$ip locked");
$result = FORBIDDEN;
last CASE;
}
my $interval = $now - $first;
$l->debug("$ip speed = ", $hits/$interval);
if ($hits/$interval > $speed_limit) {
$l->debug("$ip exceeded speed limit. Blocking.");
$locked = 1;
$result = FORBIDDEN;
last CASE;
}
}
$r->log_reason("Client exceeded speed limit.", $r->filename)
if $result == FORBIDDEN;
$DB{$id} = join " ", $first, $now, $hits, $locked;
tied(%DB)->shunlock;
return $result;
}
1;
__END__
Authentication HandlersLet's look at authentication handlers now. The authentication handler's job is to determine whether the user is who he or she claims to be, using whatever standards of proof your module chooses to apply. There are many exotic authentication technologies lurking in the wings, including smart cards, digital certificates, one-time passwords and challenge/response authentication, but at the moment the types of authentication available to modules are limited at the browser side. Most browsers only know about the user name and password system used by Basic authentication. You can design any authentication system you like, but it must ultimately rely on the user typing some information into the password dialogue box. Fortunately there's a lot you can do within this restriction, as this chapter will show.
A Simple Authentication HandlerListing 6.5 implements Apache::AuthAny, a module which will allow users to authenticate with any user name and password at all. The purpose of this module is just to show the API for a Basic authentication handler.
package Apache::AuthAny; # file: Apache/AuthAny.pm
use strict; use Apache::Constants qw(:common);
sub handler {
my $r = shift;
my($res, $sent_pw) = $r->get_basic_auth_pw;
return $res if $res != OK;
my $user = $r->connection->user;
unless($user and $sent_pw) {
$r->note_basic_auth_failure;
$r->log_reason("Both a username and password must be provided", $r->filename);
return AUTH_REQUIRED;
}
return OK; }
1; __END__
<Location /protected> AuthName Test AuthType Basic PerlAuthenHandler Apache::AuthAny require valid-user </Location> At the bottom of listing 6.5 is a short configuration file entry that activates Apache::AuthAny for all URIs that begin with the /protected path. For Basic authentication to work, protected locations must define a realm name with AuthName and specify an AuthType of Basic. In addition, in order to trigger Apache's authentication system, at least one require directive must also be present. In this example, we specify a requirement of valid-user, which is usually used to indicate that any registered user is allowed access. Last but not least, the PerlAuthenHandler directive tells mod_perl which handler to call during the authentication phase, in this case Apache::AuthAny. By the time the handler is called, Apache will have done most of the work in negotiating the HTTP Basic authentication protocol. It will have alerted the browser that authentication is required to access the page, and the browser will have prompted the user to enter his name and password. The handler needs only to recover these values and validate them. It won't take long to walk through this short module:
package Apache::AuthAny; # file: Apache/AuthAny.pm
use strict; use Apache::Constants qw(:common);
sub handler {
my $r = shift;
my($res, $sent_pw) = $r->get_basic_auth_pw;
Apache::AuthAny starts off as usual by importing the common result code constants. Upon entry its handler() subroutine immediately calls the Apache method get_basic_auth_pw(). This method returns two values: a result code and the password sent by the client. The result code will be one of the following:
return $res if $res != OK; If get_basic_auth_pw() returns OK, we continue our work. Now we need to find the username to complement the password. Because the user name may be needed by later handlers, such as the authorization and logging modules, it's stored in a stable location inside the request object's connection record. The username can be retrieved by calling the request object's connection() method to return the current Apache::Connection object, and then calling the connection object's user() method:
my $user = $r->connection->user; The values we retrieve contain exactly what the user typed into the name and password fields of the dialogue box. If the user has not yet authenticated, or pressed the submit button without filling out the dialog completely, one or both of these fields may be empty. In this case, we have to force the user to (re)authenticate:
unless($user and $sent_pw) {
$r->note_basic_auth_failure;
$r->log_reason("Both a username and password must be provided",$r->filename);
return AUTH_REQUIRED;
}
To do this, we call the request object's note_basic_auth_failure() method to add the WWW-Authenticate field to the outgoing HTTP headers. Without this call, the browser would know it had to authenticate, but would not know what authentication method and realm to use. We then log a message to the server error log using the log_reason() method and return an AUTH_REQUIRED result code to Apache. The resulting log entry will look something like this:
[Sun Jan 11 16:36:31 1998] [error] access to /protected/index.html failed for wallace.telebusiness.co.nz, reason: Both a username and password must be provided If, on the other hand, both a user name and password are present, then the user has authenticated properly. In this case we can return a result code of OK and end the handler:
return OK; } The user name will now be available to other handlers and CGI scripts. In particular, the user name will be available to any authorization handler further down the handler chain. Other handlers can simply retrieve the user name from the connection object just as we did. Notice that the Apache::AuthAny module never actually checks what is inside the username and password. Most authentication modules will compare the username and password to a pair looked up in a database of some sort. However the Apache::AuthAny module is handy for developing and testing applications that require user authentication before the real authentication module has been implemented.
An Anonymous Authentication HandlerNow we'll look at a slightly more sophisticated authentication module, Apache::AuthAnon. This module takes the basics of Apache::AuthAny and adds logic to preform some consistency checks on the username and password. This module implements anonymous authentication according to FTP conventions. The user name must be ``anonymous'' or ``anybody'', and the password must look like a valid e-mail address.Listing 6.6 gives the source code for the module. Here is a typical configuration file entry:
<Location /protected> AuthName Anonymous AuthType Basic PerlAuthenHandler Apache::AuthAnon require valid-user
PerlSetVar Anonymous anonymous|anybody </Location> Notice that the <Location> section has been changed to make Apache::AuthAnon the PerlAuthenHandler for the /protected subdirectory, and that the realm name has been changed to Anonymous. The AuthType and require directives have not changed. Even though we're not performing real user name checking, the require directive still needs to be there in order to trigger Apache's authentication handling. There is also a completely new directive, a PerlSetVar that sets the configuration directive Anonymous to a case-insensitive pattern match to perform on the provided user name. In this case, we're accepting either of the user names ``anonymous'' or ``anybody''.
Turning to the code listing, you'll see that we use the same basic outline
of Apache::AuthAny. We fetch the provided password by calling the request object's get_basic_auth_pw() method, and the user name by calling the connection object's user() method. We now perform our consistency checks on the return values. First
we check for the presence of a pattern match string in the Anonymous
configuration variable. If not present, we use a hard-coded default of
``anonymous.'' Next, we attempt to match the password against an e-mail
address pattern. While not RFC compliant, the While this example is not much more complicated than Apache::AuthAny and certainly no more secure, it does pretty much everything that a real authentication module will do. A useful enhancement to this module would be to check that the e-mail address provided by the user corresponds to a real Internet host. One way to do this is by making a call to the Perl Net::DNS module to look up the host's IP address and its mail exchanger (an ``MX'' record). If neither one nor the other is found, then it is unlikely that the e-mail address is correct.
package Apache::AuthAnon;
# file: Apathe/AuthAnon.pm
use strict;
use Apache::Constants qw(:common);
my $email_pat = '[.\w-]+\@\w+\.[.\w]*[^.]';
my $anon_id = "anonymous";
sub handler {
my $r = shift;
my($res, $sent_pwd) = $r->get_basic_auth_pw;
return $res if $res != OK;
my $user = lc $r->connection->user;
my $reason = "";
my $check_id = $r->dir_config("Anonymous") || $anon_id;
$reason = "user did not enter a valid anonymous username "
unless $user =~ /^$check_id$/i;
$reason .= "user did not enter an email address password "
unless $sent_pwd =~ /^$email_pat$/o;
if($reason) {
$r->note_basic_auth_failure;
$r->log_reason($reason,$r->filename);
return AUTH_REQUIRED;
}
$r->notes(AuthAnonPassword => $sent_pwd);
return OK;
}
1;
__END__
Authenticating Against a DatabaseLet's turn to systems that check the user's identity against a database. We debated a bit about what type of authentication database to use for these examples. Candidates included the Unix password file, the Network Information System (NIS) and Bellcore's S/Key one-time password system, but we decided that these were all too Unix-specific. So we turned back to the DBI abstract database interface, which at least is portable across Windows and Unix systems.
Chapter 5 talked about how the DBI interface works, and showed how to use Apache::DBI to avoid opening and closing database sessions with each connection. For a
little variety, we'll use Tie::DBI in this chapter. It's a simple interface to DBI database tables that makes
them look like hashes. For example, here's how to tie variable
tie %h, 'Tie::DBI', {
db => 'mysql:test_www',
table => 'user_info',
key => 'user_name',
};
The options that can be passed to tie() include db for the database source string or a previously-opened database handle, table for the name of the table to bind to (in this case ``user_info''), and key for the field to use as the hash key (in this case ``user_name''). Other options include authentication information for logging into the database. After successfully tieing the hash, you can now access the entire row keyed by user name ``fred'' like this:
$record = $h{'fred'}
and the ``passwd'' column of the row like this:
$password = $h{'fred'}{'passwd'};
Because In our examples we will be using a mySQL database named ``test_www''. It contains a table named ``user_info'' with the following structure:
+-----------+---------------+-------+---------------------+ | user_name | passwd | level | groups | +-----------+---------------+-------+---------------------+ | fred | 8uUnFnRlW18qQ | 2 | users,devel | | andrew | No9eULpnXZAjY | 2 | users | | george | V8R6zaQuOAWQU | 3 | users | | winnie | L1PKv.rN0UmsQ | 3 | users,authors,devel | | root | UOY3rvTFXJAh2 | 5 | users,authors,admin | | morgana | 93EhPjGSTjjqY | 1 | users | +-----------+---------------+-------+---------------------+ The password field is encrypted with the Unix crypt() call, which conveniently enough is available to Perl scripts as a built-in function call. The ``level'' column indicates the user's level of access to the site (higher levels indicate more access). The ``groups'' field provides a comma-delimited list of groups that the user belongs to, providing another axis along which we can perform authorization.* These will be used in later examples. Tie::DBI is not a standard part of Perl. If you don't have it, you can find it in CPAN in the modules subdirectory. You'll also need the DBI (database interface) module, and a DBD (database driver) module for the database of your choice.
#!/usr/local/bin/perl
use strict;
use Tie::DBI ();
my $DB_NAME = 'test_www';
my $DB_HOST = 'localhost';
my %test_users = (
#user_name groups level passwd
'root' => [qw(users,authors,admin 5 superman)],
'george' => [qw(users 3 jetson)],
'winnie' => [qw(users,authors,devel 3 thepooh)],
'andrew' => [qw(users 2 llama23)],
'fred' => [qw(users,devel 2 bisquet)],
'morgana' => [qw(users 1 lafey)]
);
# Sometimes it's easier to invoke a subshell for simple things
# than to use the DBI interface.
open MYSQL, "|mysql -h $DB_HOST -f $DB_NAME" or die $!;
print MYSQL <<END;
DROP TABLE user_info;
CREATE TABLE user_info (
user_name CHAR(20) primary key,
passwd CHAR(13) not null,
level TINYINT not null,
groups CHAR(100)
);
END
close MYSQL;
tie my %db, 'Tie::DBI', {
db => "mysql:$DB_NAME:$DB_HOST",
table => 'user_info',
key => 'user_name',
CLOBBER=>1,
} or die "Couldn't tie to $DB_NAME:$DB_HOST";
my $updated = 0;
for my $id (keys %test_users) {
my($groups, $level, $passwd) = @{$test_users{$id}};
$db{$id} = {
passwd => crypt($passwd, salt()),
level => $level,
groups => $groups,
};
$updated++;
}
untie %db;
print STDERR "$updated records entered.\n";
# Possible BUG: Assume that this system uses two character
# salts for its crypt().
sub salt {
my @saltset = (0..9, 'A'..'Z', 'a'..'z', '.', '/');
return join '', @saltset[rand @saltset, rand @saltset];
}
To use the database for user authentication, we take the skeleton from Apache::AuthAny and flesh it out so that it checks the provided user name and password against the corresponding fields in the database. The code for Apache::AuthTieDBI and a typical configuration file entry are given in listing 6.8. The handler() subroutine is succinct:
sub handler {
my $r = shift;
# get user's authentication credentials
my($res, $sent_pw) = $r->get_basic_auth_pw;
return $res if $res != OK;
my $user = $r->connection->user;
my $reason = authenticate($r, $user, $sent_pw);
if($reason) {
$r->note_basic_auth_failure;
$r->log_reason($reason, $r->filename);
return AUTH_REQUIRED;
}
return OK;
}
The routine begins like the previous authentication modules by fetching the user's password from get_basic_auth_pw() and username from $r->connection->user. If successful, it calls an internal subroutine named authenticate() with the request object, username and password. authenticate() returns undef on success, or an error message on failure. If an error message is returned, we log the error and return AUTH_REQUIRED. Otherwise we return OK Most of the interesting stuff happens in the authenticate() subroutine:
sub authenticate {
my($r, $user, $sent_pw) = @_;
# get configuration information
my $dsn = $r->dir_config('TieDatabase') || 'mysql:test_www';
my $table_data = $r->dir_config('TieTable') || 'users:user:passwd';
my($table, $userfield, $passfield) = split ':', $table_data;
$user && $sent_pw or return 'empty user names and passwords disallowed'; Apache::AuthTieDBI relies on two configuration variables to tell it where to look for authentication information. TieDatabase indicates what database to use in standard DBI Data Source Notation (DBI). TieTable indicates what database table and fields to use, in the form table:username_column:password_column. If these configuration variables aren't present, the module uses various hard-coded defaults. At this point the routine tries to establish contact with the database by calling tie():
tie my %DB, 'Tie::DBI', {
db => $dsn, table => $table, key => $userfield,
} or return "couldn't open database";
Provided that the Apache::DBI module was previously loaded (see Chapter 5 Storing State Information in SQL Databases), the database handle will be cached behind the scenes and there will be
no significant overhead for calling tie() once per transaction. Otherwise it would be a good idea to cache the tied
$DB{$user} or return "invalid account";
my $saved_pw = $DB{$user}{$passfield};
$saved_pw eq crypt($sent_pw, $saved_pw) or return "password mismatch";
# if we get here, all is well
return "";
}
The first line of this chunk checks whether In case you haven't used crypt() before, it takes two arguments, the plaintext password and a two or four-character ``salt'' used to seed the encryption algorithm. Different salts yield different encrypted passwords.* The returned value is the encrypted password with the salt appended at the beginning. When checking a plaintext password for correctness, it's easiest to use the encrypted password itself as the salt. Crypt() will use the first few characters as the salt and ignore the rest. If the newly encrypted value matches the stored one, then the user provided the correct plaintext password. If the encrypted password matches the saved password, we return an empty string to indicate that the checks passed. Otherwise we return an error message.
package Apache::AuthTieDBI;
use strict;
use Apache::Constants qw(:common);
use Tie::DBI ();
sub handler {
my $r = shift;
# get user's authentication credentials
my($res, $sent_pw) = $r->get_basic_auth_pw;
return $res if $res != OK;
my $user = $r->connection->user;
my $reason = authenticate($r, $user, $sent_pw);
if($reason) {
$r->note_basic_auth_failure;
$r->log_reason($reason, $r->filename);
return AUTH_REQUIRED;
}
return OK;
}
sub authenticate {
my($r, $user, $sent_pw) = @_;
# get configuration information
my $dsn = $r->dir_config('TieDatabase') || 'mysql:test_www';
my $table_data = $r->dir_config('TieTable') || 'users:user:passwd';
my($table, $userfield, $passfield) = split ':', $table_data;
$user && $sent_pw or return 'empty user names and passwords disallowed';
tie my %DB, 'Tie::DBI', {
db => $dsn, table => $table, key => $userfield,
} or return "couldn't open database";
$DB{$user} or return "invalid account";
my $saved_pw = $DB{$user}{$passfield};
$saved_pw eq crypt($sent_pw, $saved_pw) or return "password mismatch";
# if we get here, all is well
return "";
}
1;
__END__
Authorization HandlersSometimes it's good enough to know that a user can prove his or her identity, but more often that's just the beginning of the story. After authentication comes the optional authorization phase of the transaction, in which your handler gets a chance determine whether this user can fetch that URI.If you felt constrained by HTTP's obsession with conventional password checking, you can now breath a sigh of relief. Authorization schemes, as opposed to authentication, form no part of the HTTP standard. You are free to implement any scheme you can dream up. In practice, most authentication schemes are based on the user's account name, since this is the piece of information that you've just gone to some effort to confirm. What you do with that datum, however, is entirely up to you. You may look up the user in a database to determine his or her access privileges, a procedure known in security circles as ``role-based authorization.'' Or you may grant or deny access based on the name itself. We'll show a useful example of this in the next section.
A Gender-Based Authorization ModuleRemember the bar that only lets women through the door on Ladies' Night? Here's a little module that enforces that restriction. Apache::AuthzGender enforces gender-based restrictions using Jon Orwant's Text::GenderFromName, a port of an AWK script originally published by Scott Pakin in the December 1991 issue of Computer Language Monthly. Text::GenderFromName uses a set of pattern matching rules to guess people's genders from their first names, returning ``m'', ``f'' or undef for male names, female names, and names that it can't guess.Listing 6.9 gives the code and a configuration file section to go with it. In order to have a username to operate on, authentication has to be active. This means there must be AuthName and AuthType directives, as well as a require statement. You can use any authentication method you choose, including the standard text, DBM and DB modules. In this case, we use Apache::AuthAny from the example earlier in this chapter because it provides a way of passing in arbitrary user names. In addition to the standard directives, Apache::AuthzGender accepts a configuration variable named Gender. Gender can be either of the characters ``M'' or ``F'', to allow access by people of the male and female persuasions respectively. Turning to the code (listing 6.9), the handler() subroutine begins by retrieving the user name by calling the connection object's user(). method. We know this value is defined because it was set during authentication. Next we recover the value of the Gender configuration variable.
We now apply the Text::GenderFromName module's gender() function to the username and compare the result to the desired value. There
are a couple of details to worry about. First, If there's a mismatch, authorization has failed. We indicate this in exactly the way we do in authorization modules, by calling the request object's note_basic_auth_failure() method, writing a line to the log, and returning a status code of AUTH_REQUIRED. If the test succeeds, we return OK.
package Apache::AuthzGender;
use strict;
use Text::GenderFromName qw(gender);
use Apache::Constants qw(:common);
sub handler {
my $r = shift;
my $user = ucfirst lc $r->connection->user;
my $gender = uc($r->dir_config('Gender')) || 'F';
my $guessed_gender = uc(gender($user)) || 'M';
unless ($guessed_gender eq $gender) {
$r->note_basic_auth_failure;
$r->log_reason("$user is of wrong apparent gender", $r->filename);
return AUTH_REQUIRED;
}
return OK;
}
1;
__END__
<Location /ladies_only> AuthName Restricted AuthType Basic PerlAuthenHandler Apache::AuthAny PerlAuthzHandler Apache::AuthzGender PerlSetVar Gender F require valid-user </Location>
Advanced Gender-Based AuthorizationA dissatisfying feature of Apache::AuthzGender is that when an unauthorized user finally gives up and presses the ``Cancel'' button, Apache displays the generic ``Unauthorized'' error page without providing any indication of why the user was refused access. Fortunately this is easy to fix with a custom error response. We can call the request object's custom_response() method to display a custom error message, an HTML page, or the output of a CGI script when the AUTH_REQUIRED error occurs.Another problem with Apache::AuthzGender is that it uses a nonstandard way to configure the authorization scheme. The standard authorization schemes use a require directive as in:
require group authors At the cost of making our module slightly more complicated, we can accommodate this too, allowing access to the protected directory to be adjusted by any of the following directives:
require gender F # allow females require user Webmaster Jeff # allow Webmaster or Jeff require valid-user # allow any valid user Listing 6.10 shows an improved Apache::AuthzGender that implements these changes. The big task is to recover and process the list of require directives. To retrieve the directives, we call the request object's requires() method. This method returns an array reference corresponding to all of the require directives in the current directory and its parents. Rather than being a simple string, however, each member of this array is actually a hash reference containing two keys, method_mask and requirement. The requirement key is easy to understand. It's simply all the text to the right of the require directive (excluding comments). You'll process this text according to your own rules. There's nothing magical about the keywords ``user,'' ``group,'' or ``valid-user.'' The method_mask key is harder to explain. It consists of a bit mask indicating what methods the require statement should be applied to. This mask is set when there are one or more <LIMIT> sections in the directory's configuration. The GET, PUT, POST and DELETE methods correspond to the first through fourth bits of the mask (counting from the right). For example, a require directive contained within a <LIMIT GET POST> section will have a method mask equal to binary 0101, or decimal 5. If no <LIMIT> section is present, the method mask will be -1 (all bits set, all methods restricted). You can test for particular bits using the method number constants defined in the ``:methods'' section of Apache::Constants. For example, to test whether the current mask applies to POST requests, you could write a piece of code like this one (assuming that the current requires() is in $_):
if ($_->{method_mask} & (1 << M_POST)) {
warn "Current requirements apply to POST";
}
In practice, you rarely have to worry about the method mask within your own authorization modules, because mod_perl automatically filters out any require statement that wouldn't apply to the current transaction. In the example given above, the array reference returned by requires() would look like this:
[
{
requirement => 'gender F',
method_mask => -1
},
{
requirement => 'user Webmaster Jeff',
method_mask => -1
},
{
requirement => 'valid-user',
method_mask => -1
}
]
The revised module begins by calling the request object's requires()
method and storing it in a lexical variable
my $r = shift; my $requires = $r->requires; return DECLINED unless $requires; If requires() returns undef, it means that no require statements were present, so we decline to handle the transaction. (This shouldn't actually happen, but it doesn't hurt to make sure.) The script then recovers the user's name and guesses his or her gender, as before. Next we begin our custom error message:
my $explanation = <<END; <TITLE>Unauthorized</TITLE> <H1>You Are Not Authorized to Access This Page</H1> Access to this page is limited to: <OL> END The message will be in a text/html page, so we're free to use HTML formatting. The error warns that the user is unauthorized, followed by a numbered list of the requirements that the user must meet in order to gain access to the page (Figure 6.2). This will help us confirm that the requirement processing is working correctly.
$requires:
for my $entry (@$requires) {
my($requirement, @rest) = split /\s+/, $entry->{requirement};
For each requirement, we extract the text of the require directive and split it on whitespace into the requirement type and its arguments. For example, the line ``require gender M'' would result in a requirement type of ``gender'' and an argument of ``M''. We act on any of three different requirement types. If the requirement equals ``user'', we loop through its arguments seeing if the current user matches any of the indicated user names. If a match is found, we exit with an OK result code:
if (lc $requirement eq 'user') {
foreach (@rest) { return OK if $user eq $_; }
$explanation .= "<LI>Users @rest.\n";
}
If the requirement equals ``gender'', we loop through its arguments looking to see whether the user's gender is correct* and again return OK if a match is found:
elsif (lc $requirement eq 'gender') {
foreach (@rest) { return OK if $guessed_gender eq uc $_; }
$explanation .= "<LI>People of the @G{@rest} persuasion.\n";
}
Otherwise, if the requirement equals ``valid-user'' then we simply return OK, because the authentication module has already made sure of this for us:
elsif (lc $requirement eq 'valid-user') {
return OK;
}
}
$explanation .= "</OL>";
As we process each require directive, we add a line of explanation to the custom error string. We never use this error string if any of the requirements are satisfied, but if we fall through to the end of the loop, we complete the ordered list and set the explanation as the response for AUTH_REQUIRED errors by passing the explanation string to the request object's custom_response() method:
$r->custom_response(AUTH_REQUIRED, $explanation); The module ends by noting and logging the failure, and returning an AUTH_REQUIRED status code as before:
$r->note_basic_auth_failure;
$r->log_reason("user $user: not authorized", $r->filename);
return AUTH_REQUIRED;
}
The logic of this module places a logical OR between the requirements. The user is allowed access to the site if any of the require statements is satisfied, which is consistent with the way Apache handles authorization in its standard modules. However, you can easily modify the logic so that all requirements must be met in order to allow the user access.
package Apache::AuthzGender2;
use strict;
use Text::GenderFromName qw(gender);
use Apache::Constants qw(:common);
my %G = ('M' => "male", 'F' => "female");
sub handler {
my $r = shift;
my $requires = $r->requires;
return DECLINED unless $requires;
my $user = ucfirst lc $r->connection->user;
my $guessed_gender = uc(gender($user)) || 'M';
my $explanation = <<END;
<TITLE>Unauthorized</TITLE>
<H1>You Are Not Authorized to Access This Page</H1>
Access to this page is limited to:
<OL>
END
for my $entry (@$requires) {
my($requirement, @rest) = split /\s+/, $entry->{requirement};
if (lc $requirement eq 'user') {
foreach (@rest) { return OK if $user eq $_; }
$explanation .= "<LI>Users @rest.\n";
}
elsif (lc $requirement eq 'gender') {
foreach (@rest) { return OK if $guessed_gender eq uc $_; }
$explanation .= "<LI>People of the @G{@rest} persuasion.\n";
}
elsif (lc $requirement eq 'valid-user') {
return OK;
}
}
$explanation .= "</OL>";
$r->custom_response(AUTH_REQUIRED, $explanation);
$r->note_basic_auth_failure;
$r->log_reason("user $user: not authorized", $r->filename);
return AUTH_REQUIRED;
}
1;
__END__
Authorizing Against a DatabaseIn most real applications you'll be authorizing users against a database of some sort. This section will show you a simple scheme for doing this that works hand-in-glove with the Apache::AuthTieDBI database authentication system that we set up in the Authenticating Against a Database section earlier in this chapter. To avoid making you page backwards, we repeat the contents of the test database here:
+-----------+---------------+-------+---------------------+ | user_name | passwd | level | groups | +-----------+---------------+-------+---------------------+ | fred | 8uUnFnRlW18qQ | 2 | users,devel | | andrew | No9eULpnXZAjY | 2 | users | | george | V8R6zaQuOAWQU | 3 | users | | winnie | L1PKv.rN0UmsQ | 3 | users,authors,devel | | root | UOY3rvTFXJAh2 | 5 | users,authors,admin | | morgana | 93EhPjGSTjjqY | 1 | users | +-----------+---------------+-------+---------------------+ The module is called Apache::AuthzTieDBI, and the idea is to allow for ``require'' statements like these:
require $user_name eq 'fred' require $level >=2 && $groups =~ /\bauthors\b/; require $groups =~/\b(users|admin)\b/ Each require directive consists of an arbitrary Perl expression. During evaluation, variable names are replaced by the name of the corresponding column in the database. In the first example above, we require the user name to be exactly ``fred''. In the second case, we allow access by any user whose level is greater or equal than 2 and who belongs to the ``authors'' group. In the third case, anyone whose groups field contains either of the strings ``users'' or ``admin'' is allowed in. As in the previous examples, the require statements are ORed with each other. If multiple require statements are present, the user has to satisfy only one of them in order to be granted access. The directive require valid-user is treated as a special case and not evaluated as a Perl expression.
Listing 6.11 shows the code to accomplish this. Much of it is stolen
directly out of Apache::AuthTieDBI, so we won't review how the database is opened and tied to the
if ($DB{$user}) { # evaluate each requirement
for my $entry (@$requires) {
my $op = $entry->{requirement};
return OK if $op eq 'valid-user';
$op =~ s/\$\{?(\w+)\}?/\$DB{'$user'}{$1}/g;
return OK if eval $op;
$r->log_error($@) if $@;
}
}
After making sure that the user actually exists in the database, we loop through each of the require statements and recover its raw text. We then construct a short string to evaluate, replacing anything that looks like a variable with the appropriate reference to the tied database hash. We next call eval() and return OK if a true value is returned. If none of the require statements evaluate to true, we log the problem, note the authentication failure, and return AUTH_REQUIRED. That's all there is to it! Although this scheme works well and is actually quite flexible in practice, you should be aware of one small problem with it before you rush off and implement it on your server. Because the module is calling eval() on Perl code read in from the configuration file, anyone who has write access to the file or to any of the per-directory .htaccess files can make this module execute Perl instructions with the server's privileges. If you have any authors at your site who you don't fully trust, you might think twice about making this facility available to them. A good precaution would be to modify this module to use the Safe module. Add the following to the top of the module:
use Safe ();
sub safe_eval {
package main;
my($db, $code) = @_;
my $cpt = Safe->new;
local *DB = $db;
$cpt->share('%DB', '%Tie::DBI::', '%DBI::', '%DBD::');
return $cpt->reval($code);
}
The safe_eval() subroutine creates a safe compartment and shares the To use this routine modify the call to eval() in the inner loop to call save_eval():
return OK if safe_eval(\%DB, $op); The code will now be execute in a compartment in which dangerous calls like system() and unlink() have been disabled. With suitable modifications to the shared namespaces, this routine can also be used in other places where you might be tempted to run eval().
package Apache::AuthzTieDBI;
# file: Apache/AuthTieDBI.pm
use strict;
use Apache::Constants qw(:common);
use Tie::DBI ();
sub handler {
my $r = shift;
my $requires = $r->requires;
return DECLINED unless $requires;
my $user = $r->connection->user;
# get configuration information
my $dsn = $r->dir_config('TieDatabase') || 'mysql:test_www';
my $table_data = $r->dir_config('TieTable') || 'users:user:passwd';
my($table, $userfield, $passfield) = split ':', $table_data;
tie my %DB, 'Tie::DBI', {
db => $dsn, table => $table, key => $userfield,
} or die "couldn't open database";
if ($DB{$user}) { # evaluate each requirement
for my $entry (@$requires) {
my $op = $entry->{requirement};
return OK if $op eq 'valid-user';
$op =~ s/\$\{?(\w+)\}?/\$DB{'$user'}{$1}/g;
return OK if eval $op;
$r->log_error($@) if $@;
}
}
$r->note_basic_auth_failure;
$r->log_reason("user $user: not authorized", $r->filename);
return AUTH_REQUIRED;
}
1;
__END__
Authentication and Authorization's Relationship with SubrequestsIf you have been trying out the examples so far, you may notice that the authentication and authorization handlers are called more than once for certain requests. Chances are, these requests have been for a / directory, where the actual file sent back is one configured with the DirectoryIndex directive, such as index.html or index.cgi. For each file listed in the DirectoryIndex configuration, Apache will run a subrequest to determine if the file exists and has sufficent permissions to use in the response. As we learned in chapter 3, a subrequest will trigger the various request phase handlers, including authentication and authorization. Depending on the resources required to provide these services, it may not be desirable for the handlers to run more than once for a given HTTP request. Auth handlers can avoid being called more than once by using the is_initial_req() method, for example:
sub handler {
my $r = shift;
return OK unless $r->is_initial_req;
...
With this test in place, the main body of the handler will only be run once per HTTP request, during the very first internal request. Note that this approach should be used with caution, taking your server access configuration into consideration.
Binding Authentication to AuthorizationAuthorization and authentication work together. Often, as we saw in the previous example, you find PerlAuthenHandler and PerlAuthzHandlers side by side in the same access control section. If you have a pair of handlers that were designed to work together, and only together, you simplify the directory configuration somewhat by binding the two together so that you need only specify the authentication handler.To accomplish this trick, have the authentication handler call push_handlers() with a reference to the authorization handler code before it exits. Because the authentication handler is always called before the authorization handler, this will temporarily place your code on the handler list. After processing the transaction, the authorization handler is set back to its default. In the case of Apache::AuthTieDBI and Apache::AuthzTieDBI, the only change we need to make is to place the following line of code in Apache::AuthTieDBI somewhere towards the top of the handler subroutine:
$r->push_handlers(PerlAuthzHandler => \&Apache::AuthzTieDBI::handler); We now need to bring in Apache::AuthTieDBI only. The authorization handler will automatically come along for the ride.
<Location /registered_users> AuthName Enlightenment AuthType Basic PerlAuthenHandler Apache::AuthTieDBI PerlSetVar TieDatabase mysql:test_www PerlSetVar TieTable user_info:user_name:passwd require $user_name eq 'fred' require $level >=2 && $groups =~ /authors/; </Location> Since the authentication and authorization modules usually share common code, it might make sense to merge the authorization and authentication handlers into the same .pm file. This scheme allows you to do that. Just rename the authorization subroutine to something like authorize() and keep handler() as the entry point for the authentication code. Then at the top of handler() include a line like this:
$r->push_handlers(PerlAuthzHandler => \&authorize); We can now remove redundant code from the two handlers. For example, in the Apache::AuthTieDBI modules, there is common code that retrieves the per-directory configuration variables and opens the database. This can now be merged into a single initialization subroutine.
Cookie-Based Access ControlThe next example is a long one. To understand its motivation, consider a large site that runs not one, but multiple Web servers. Perhaps each server mirrors the others in order to spread out and reduce the load, or maybe each server is responsible for a different part of the site.Such a site might very well want to have each of the servers perform authentication and access control against a shared database, but if it does so in the obvious way it faces some potential problems. In order for each of the servers to authenticate against a common database, they will have to connect to it via the network. But this is less than ideal because connecting to a network database is not nearly so fast as connecting to a local one. Furthermore the database network connections generate a lot of network overhead, and compete with the Web server for a limited pool of operating system file descriptors. The performance problem is aggravated if authentication requires the evaluation of a complex SQL statement rather than a simple record lookup. There are also security issues to consider when using a common authentication database. If the database holds confidential information, such as customer account information, it wouldn't do to give all the Web servers free access to the database. A breakin on any of the Web servers could compromise the confidentiality of the information. Apache::TicketAccess was designed to handle these and other situations in which user authentication is expensive. Instead of performing a full authentication each time the user requests a page, the module only authenticates against a relational database the very first time the user connects (see Figure 6.3). After successfully validating the user's identity, the user is issued a ``ticket'' to use for subsequent accesses. This ticket, which is no more than an HTTP cookie, carries the user's name, IP address, an expiration date, and a cryptographic signature. Until it expires, the ticket can be used to gain entry to any of the servers at the site. Once a ticket is issued, validating it is fast; the servers merely check the signature against the other information on the ticket to make sure that it hasn't been tampered with. No further database accesses are necessary. In fact, only the machine that actually issues the tickets, the so-called ``ticket master'', requires database connectivity.
Another use for a system like this is to implement non-standard authentication schemes, such as a one-time password or a challenge-response system. The server that issues tickets doesn't need to use Basic authentication. Instead it can verify the identity of the user in any way that it sees fit. It can ask the user for his mother's maiden name... or enter the value that appears on a SecureID card. Once the ticket is issued, no further user interaction is required. The key to the ticket system is the MD5 hash algorithm, which we previously used in Chapter 5 to create message authentication checks (MACs). As in that chapter, we will use MD5 here to create authenticated cookies that cannot be tampered or forged. If you don't already have it, MD5 can be found in CPAN under the modules directory. The tickets used in this system have a structure that looks something like this:
IP=$IP time=$time expires=$expires user=$user_name hash=$hash The hash is an MD5 digest that is calculated according to this formula:
my $hash=MD5->hexhash($secret . MD5->hexhash(join ":", $secret, $IP, $time, $expires, $user_name) ); The other fields are explained below:
We use two rounds of MD5 digestion to compute the hash rather than one. This prevents a malicious user from appending extra information to the end of the ticket by exploiting one of the mathematical properties of the MD5 algorithm. Although it is unlikely that this would present a problem here, it is always a good idea to plug this known vulnerability. The secret key is the lynchpin of the whole scheme. Because the secret key is known only to the servers and not to the rest of the world, only a trusted Web server can issue and validate the ticket. However, there is the technical problem of sharing the secret key among the servers in a secure manner. If the key were intercepted, the interloper could write his own tickets. In this module, we use either of two methods for sharing the secret key. The secret key may be stored in a file located on the file system, in which case it is the responsibility of the system administrator to distribute it among the various servers that use it (NFS is one option, rdist, FTP, or secure shell are others). The module also allows the secret to be fetched from a central Web server via a URL. The system administrator must configure the configuration files so that only internal hosts are allowed to access it. We'll take a top-down approach to the module starting with the access control handler implemented by the machines that accept tickets. Listing 6.12 gives the code for Apache::TicketAccess and a typical entry in the configuration file. The relevant configuration directives look like this:
PerlAccessHandler Apache::TicketAccess PerlSetVar TicketDomain .capricorn.org PerlSetVar TicketSecret http://master.capricorn.org/secrets/key.txt ErrorDocument 403 http://master.capricorn.org/ticketLogin These directives set the access control handler to use Apache::TicketAccess, and set two per-directory configuration variables using PerlSetVar. TicketDomain is the DNS domain over which issued tickets are valid. If not specified, the module will attempt to guess it from the server host name, but it's best to specify that information explicitly. TicketSecret is the URL where the shared secret key can be found. It can be on the same server or a different one. Instead of giving a URL, you may specify a physical path to a file on the local system. The contents of the file will be used as the secret. The last line is an ErrorDocument directive that redirects 403 (``Forbidden'') errors to a URI on the ticket master machine. If a client fails to produce a valid ticket -- or has no ticket at all -- the Web server it tried to access will reject the request, causing Apache to redirect the client to the ticket master URI. The ticket master will handle the details of authentication and authorization, give the client a ticket, and then redirect it back to the original server. Turning to the code for Apache::TicketAccess, you'll find that it's extremely short because all the dirty work is done in a common utility library named Apache::TicketTool. The handler fetches the request object and uses it to create a new TicketTool object. The TicketTool is responsible for fetching the per-directory configuration options, recovering the ticket from the HTTP headers, and fetching the secret key. Next we call the TicketTool's verify_ticket() method to return a result code and an error message. If the result code is true, we return OK. If verify_ticket() returns false, we do something a bit more interesting. We're going to set in motion a chain of events that leads to the client being redirected to the server responsible for issuing tickets. However, after issuing the ticket we want the ticket master to redirect the browser back to the original page it tried to access. If the ticket issuer happens to be the same as the current server, we can (and do) recover this information from the Apache subrequest record. However, in the general case the server that issues the ticket is not the same as the current one, so we have to cajole the browser into transmitting the URI of the current request to the issuer.
To do this, we invoke the TicketTool object's
make_return_address() method to create a temporary cookie that contains the current request's
URI. We then add this cookie to the error headers by calling the request
object's err_header_out()
method. We then return a
package Apache::TicketAccess;
use strict;
use Apache::Constants qw(:common);
use Apache::TicketTool ();
sub handler {
my $r = shift;
my $ticketTool = Apache::TicketTool->new($r);
my($result, $msg) = $ticketTool->verify_ticket($r);
unless ($result) {
$r->log_reason($msg, $r->filename);
my $cookie = $ticketTool->make_return_address($r);
$r->err_headers_out->add('Set-Cookie' => $cookie);
return FORBIDDEN;
}
return OK;
}
1;
__END__
<Location /protected> PerlAccessHandler Apache::TicketAccess PerlSetVar TicketDomain .capricorn.org PerlSetVar TicketSecret http://master.capricorn.org/secrets/key.txt ErrorDocument 403 http://master.capricorn.org/ticketLogin </Location> Now let's have a look at the code to authenticate users and issue tickets. Listing 6.13 shows Apache::TicketMaster, the module that runs on the central authentication server, along with a sample configuration file entry. For the ticket issuer, the configuration is somewhat longer than the previous one, reflecting its more complex role:
SetHandler perl-script PerlHandler Apache::TicketMaster PerlSetVar TicketDomain .capricorn.org PerlSetVar TicketSecret http://master.capricorn.org/secrets/key.txt PerlSetVar TicketDatabase mysql:test_www PerlSetVar TicketTable user_info:user_name:passwd PerlSetVar TicketExpires 10 We define a URI called /ticketLogin. The name of this URI is arbitrary, but it must match the URI given in protected directories' ErrorDocument directive. This module is a standard content handler rather than an authentication handler. Not only does this design allow us to create a custom login screen (Figure 6.4), but we can design our own authentication system, such as one based on answering a series of questions correctly. Therefore we set the Apache handler to perl-script and use a vanilla PerlHandler directive to set the content handler to Apache::TicketMaster.
The last three per-directory configuration variables are specific to the ticket issuer. TicketDatabase indicates the relational database to use for authentication. It consists of the DBI driver and the database name separated by colons. TicketTable tells the module where it can find user names and passwords within the database. It consists of the table name, the user name column and the password column all separated by colons. The last configuration variable, TicketExpires, contains the time (expressed in minutes) for which the issued ticket is valid. After this period of time the ticket expires and the user has to reauthenticate. In this system we measure ticket expiration time from the time that it was issued. If you wish, you could modify the logic so that the ticket expires only after a certain period of inactivity. The code is a little longer than Apache::TicketAccess. We'll walk through the relevant parts.
package Apache::TicketMaster; use strict; use Apache::Constants qw(:common); use Apache::TicketTool (); use CGI '-autoload'; Apache::TicketMaster loads Apache::Constants, the Apache::TicketTool module and CGI.pm, which will be used for its HTML shortcuts.
sub handler {
my $r = shift;
my($user, $pass) = map { param($_) } qw(user password);
Using the reverse logic typical of CGI scripts, the handler() subroutine first checks to see whether script parameters named user and password are already defined, indicating that the user has submitted the fill-out form.
my $request_uri = param('request_uri') ||
($r->prev ? $r->prev->uri : cookie('request_uri'));
unless ($request_uri) {
no_cookie_error();
return OK;
}
The subroutine then attempts to recover the URI of the page that the user attempted to fetch before being bumped here. The logic is only a bit twisted. First, we look for a hidden CGI parameter named request_uri. This might be present if the user failed to authenticate the first time and resubmits the form. If this parameter isn't present, we check the request object to see whether this request is the result of an internal redirect, which will happen when the same server both accepts and issues tickets. If there is a previous request, we recover its URI. Otherwise, the client may have been referred to us via an external redirect. Using CGI.pm's cookie() method, we check the request for a cookie named request_uri and recover its value. If we've looked in all these diverse locations and still don't have a location, something's wrong. The most probable explanation is that the user's browser doesn't accept cookies, or the user has turned cookies off. Since the whole security scheme depends on cookies being active, we call an error routine named no_cookie_error() that gripes at the user for failing to configure his browser correctly.
my $ticketTool = Apache::TicketTool->new($r);
my($result, $msg);
if ($user and $pass) {
($result, $msg) = $ticketTool->authenticate($user, $pass);
if ($result) {
my $ticket = $ticketTool->make_ticket($r, $user);
unless ($ticket) {
$r->log_error("Couldn't make ticket -- missing secret?");
return SERVER_ERROR;
}
go_to_uri($r, $request_uri, $ticket);
return OK;
}
}
make_login_screen($msg, $request_uri);
return OK;
}
We now go on to authenticate the user. We create a new TicketTool from the request object. If both the username and password fields are filled in, we call on TicketTool's authenticate() method to confirm the user's ID against the database. If this is successful, we call make_ticket() to create a cookie containing the ticket information, and invoke our go_to_uri() subroutine to redirect the user back to the original URI. If authentication fails, we display an error message and prompt the user to try the log in again. If the authentication succeeds, but TicketTool fails to return a ticket for some reason, we exit with a server error. This scenario only happens if the secret key can not be read. Finally, if either the username or password are missing, or if the authentication attempt failed, we call make_login_screen() to display the sign-in page. The make_login_screen() and no_cookie_error() subroutines are straightforward, so we won't go over them. However go_to_uri() is more interesting:
sub go_to_uri {
my($r, $requested_uri, $ticket) = @_;
print header(-refresh => "1; URL=$requested_uri", -cookie => $ticket),
start_html(-title => 'Successfully Authenticated', -bgcolor => 'white'),
h1('Congratulations'),
h2('You have successfully authenticated'),
h3("Please stand by..."),
end_html();
}
This subroutine uses CGI.pm methods to create an HTML page that briefly displays a message that the user has successfully authenticated, and then automatically loads the page that the user tried to access in the first place. This magic is accomplished by adding a Refresh field to the HTTP header, with a refresh time of one second and a refresh URL of the original page. At the same time we issue an HTTP cookie containing the ticket created during the authentication process.
package Apache::TicketMaster;
use strict;
use Apache::Constants qw(:common);
use Apache::TicketTool ();
use CGI '-autoload';
# This is the log-in screen that provides authentication cookies.
# There should already be a cookie named "request_uri" that tells
# the login screen where the original request came from.
sub handler {
my $r = shift;
my($user, $pass) = map { param($_) } qw(user password);
my $request_uri = param('request_uri') ||
($r->prev ? $r->prev->uri : cookie('request_uri'));
unless ($request_uri) {
no_cookie_error();
return OK;
}
my $ticketTool = Apache::TicketTool->new($r);
my($result, $msg);
if ($user and $pass) {
($result, $msg) = $ticketTool->authenticate($user, $pass);
if ($result) {
my $ticket = $ticketTool->make_ticket($r, $user);
unless ($ticket) {
$r->log_error("Couldn't make ticket -- missing secret?");
return SERVER_ERROR;
}
go_to_uri($r, $request_uri, $ticket);
return OK;
}
}
make_login_screen($msg, $request_uri);
return OK;
}
sub go_to_uri {
my($r, $requested_uri, $ticket) = @_;
print header(-refresh => "1; URL=$requested_uri", -cookie => $ticket),
start_html(-title => 'Successfully Authenticated', -bgcolor => 'white'),
h1('Congratulations'),
h2('You have successfully authenticated'),
h3("Please stand by..."),
end_html();
}
sub make_login_screen {
my($msg, $request_uri) = @_;
print header(),
start_html(-title => 'Log In', -bgcolor => 'white'),
h1('Please Log In');
print h2(font({color => 'red'}, "Error: $msg")) if $msg;
print start_form(-action => script_name()),
table(
Tr(td(['Name', textfield(-name => 'user')])),
Tr(td(['Password', password_field(-name => 'password')]))
),
hidden(-name => 'request_uri', -value => $request_uri),
submit('Log In'), p(),
end_form(),
em('Note: '),
"You must set your browser to accept cookies in order for login to succeed.",
"You will be asked to log in again after some period of time has elapsed.";
}
# called when the user tries to log in without a cookie
sub no_cookie_error {
print header(),
start_html(-title => 'Unable to Log In', -bgcolor => 'white'),
h1('Unable to Log In'),
"This site uses cookies for its own security. Your browser must be capable ",
"of processing cookies ", em('and'), " cookies must be activated. ",
"Please set your browser to accept cookies, then press the ",
strong('reload'), " button.", hr();
}
1;
__END__
<Location /ticketLogin> SetHandler perl-script PerlHandler Apache::TicketMaster PerlSetVar TicketDomain .capricorn.org PerlSetVar TicketSecret http://master.capricorn.org/secrets/key.txt PerlSetVar TicketDatabase mysql:test_www PerlSetVar TicketTable user_info:user_name:passwd PerlSetVar TicketExpires 10 </Location> By now you're probably anxious to see how Apache::TicketTool works, so let's have a look at it (Listing 6.14).
package Apache::TicketTool; use strict; use Tie::DBI (); use CGI::Cookie (); use MD5 (); use LWP::Simple (); use Apache::File (); use Apache::URI (); We start by importing the modules we need, including Tie::DBI, CGI::Cookie and the MD5 module.
my $ServerName = Apache->server->server_hostname; my %DEFAULTS = ( 'TicketDatabase' => 'mysql:test_www', 'TicketTable' => 'user_info:user_name:passwd', 'TicketExpires' => 30, 'TicketSecret' => 'http://$ServerName/secret_key.txt', 'TicketDomain' => undef, ); my %CACHE; # cache objects by their parameters to minimize time-consuming operations
Next we define some default variables that were used during testing and
development of the code, and an object cache named
sub new {
my($class, $r) = @_;
my %self = ();
foreach (keys %DEFAULTS) {
$self{$_} = $r->dir_config($_) || $DEFAULTS{$_};
}
# post-process TicketDatabase and TicketDomain
($self{TicketDomain} = $ServerName) =~ s/^[^.]+//
unless $self{TicketDomain};
# try to return from cache
my $id = join '', sort values %self;
return $CACHE{$id} if $CACHE{$id};
# otherwise create new object
return $CACHE{$id} = bless \%self, $class;
}
The TicketTool new() method is responsible for initializing a new TicketTool object, or fetching an appropriate old one from the cache. It reads the per-directory configuration variables from the passed request object, and merges them with the defaults. If no TicketDomain variable is present, it attempts to guess one from the server hostname. The code that manages the cache indexes the cache array with the values of the per-directory variables so that several different configurations can coexist peacefully.
sub authenticate {
my($self, $user, $passwd) = @_;
my($table, $userfield, $passwdfield) = split ':', $self->{TicketTable};
tie my %DB, 'Tie::DBI', {
'db' => $self->{TicketDatabase},
'table' => $table, 'key' => $userfield,
} or return (undef, "couldn't open database");
return (undef, "invalid account")
unless $DB{$user};
my $saved_passwd = $DB{$user}->{$passwdfield};
return (undef, "password mismatch")
unless $saved_passwd eq crypt($passwd, $saved_passwd);
return (1, '');
}
The authenticate() method is called by the ticket issuer to authenticate a user name and password against a relational database. This method is just a rehash of the database authentication code that we have seen in previous sections.
sub fetch_secret {
my $self = shift;
unless ($self->{SECRET_KEY}) {
if ($self->{TicketSecret} =~ /^http:/) {
$self->{SECRET_KEY} = LWP::Simple::get($self->{TicketSecret});
} else {
my $fh = Apache::File->new($self->{TicketSecret}) || return undef;
$self->{SECRET_KEY} = <$fh>;
}
}
$self->{SECRET_KEY};
}
The fetch_secret() method is responsible for fetching the secret key from disk or via the Web. The subroutine first checks to see whether there is already a secret key cached in memory and returns that if present. Otherwise it examines the value of the TicketSecret variable. If it looks like a URL, we load the LWP ``Simple'' module and use it to fetch the contents of the URL.* If TicketSecret doesn't look like a URL, we attempt to open it as a physical path name using Apache::File methods, and read its contents. We cache the result and return it.
sub invalidate_secret { undef shift->{SECRET_KEY}; }
The invalidate_secret() method is called whenever there seems to be a mismatch between the current secret and the cached one. This method deletes the cached secret, forcing it to be reloaded the next time it's needed. The make_ticket() and verify_ticket() methods are responsible for issuing and checking tickets.
sub make_ticket {
my($self, $r, $user_name) = @_;
my $ip_address = $r->connection->remote_ip;
my $expires = $self->{TicketExpires};
my $now = time;
my $secret = $self->fetch_secret() or return undef;
my $hash = MD5->hexhash($secret .
MD5->hexhash(join ':', $secret, $ip_address, $now,
$expires, $user_name)
);
return CGI::Cookie->new(-name => 'Ticket',
-path => '/',
-domain => $self->{TicketDomain},
-value => {
'ip' => $ip_address,
'time' => $now,
'user' => $user_name,
'hash' => $hash,
'expires' => $expires,
});
}
make_ticket() gets the user's name from the caller, his browser's IP address from the request object, the expiration time from the value of the TicketExpires configuration variable, and the secret key from the fetch_secret() method. It then concatenates these values along with the current system time and calls MD5's hexhash() method to turn them into an MD5 digest. The routine now incorporates this digest into an HTTP cookie named ``Ticket'' by calling CGI::Cookie->new(). The cookie contains the hashed information, along with plaintext versions of everything except for the secret key. A cute feature of CGI::Cookie is that it serializes simple data structures, allowing you to turn hashes into cookies and later recover them. The cookie's domain is set to the value of TicketDomain, ensuring that the cookie will be sent to all servers in the indicated domain. Note that the cookie itself has no expiration date. This tells the browser to keep the cookie in memory only until the user quits the application. The cookie is never written to disk.
sub verify_ticket {
my($self, $r) = @_;
my %cookies = CGI::Cookie->parse($r->header_in('Cookie'));
return (0, 'user has no cookies') unless %cookies;
return (0, 'user has no ticket') unless $cookies{'Ticket'};
my %ticket = $cookies{'Ticket'}->value;
return (0, 'malformed ticket')
unless $ticket{'hash'} && $ticket{'user'} &&
$ticket{'time'} && $ticket{'expires'};
return (0, 'IP address mismatch in ticket')
unless $ticket{'ip'} eq $r->connection->remote_ip;
return (0, 'ticket has expired')
unless (time - $ticket{'time'})/60 < $ticket{'expires'};
my $secret;
return (0, "can't retrieve secret")
unless $secret = $self->fetch_secret;
my $newhash = MD5->hexhash($secret .
MD5->hexhash(join ':', $secret,
@ticket{qw(ip time expires user)})
);
unless ($newhash eq $ticket{'hash'}) {
$self->invalidate_secret; #maybe it's changed?
return (0, 'ticket mismatch');
}
$r->connection->user($ticket{'user'});
return (1, 'ok');
}
verify_ticket() does the same thing, but in reverse. It calls CGI::Cookie->parse() to parse all cookies passed in the HTTP header and stow them into a hash. The method then looks for a cookie named ``Ticket''. If one is found, it recovers each of the ticket's fields, and does some consistency checks. The method returns an error if any of the ticket fields are missing, if the request's IP address doesn't match the ticket's IP address, or if the ticket has expired.
verify_ticket() then calls secret_key() to get the current value of the secret key, and recomputes the hash. If the
new hash doesn't match the old one, then either the secret key has changed
since the ticket was issued, or the ticket is a forgery. In either case, we
invalidate the cached secret and return false, forcing the user to repeat
the formal authentication process with the central server. Otherwise the
function saves the username in the connection object by calling $r->connection->user($ticket{'user'}) and returns true result code. The username is saved into the connection
object at this point so that authorization and logging handlers will have
access to it. It also makes the username available to CGI scripts via the
sub make_return_address {
my($self, $r) = @_;
my $uri = Apache::URI->parse($r, $r->uri);
$uri->scheme("http");
$uri->hostname($r->get_server_name);
$uri->port($r->get_server_port);
$uri->query(scalar $r->args);
return CGI::Cookie->new(-name => 'request_uri',
-value => $uri->unparse,
-domain => $self->{TicketDomain},
-path => '/');
}
The last method, make_return_address(), is responsible for creating a cookie to transmit the URI of the current request to the central authentication server. It recovers the server hostname, port, path and CGI variables from the request object, and turns it into a full URI. It then calls CGI::Cookie->new() to incorporate this URI into a cookie named ``request_uri'', which it returns to the caller. scheme(), hostname() and the other URI processing calls are explained in detail in Chapter 9, under The Apache::URI Class.
package Apache::TicketTool;
use strict;
use Tie::DBI ();
use CGI::Cookie ();
use MD5 ();
use LWP::Simple ();
use Apache::File ();
use Apache::URI ();
my $ServerName = Apache->server->server_hostname;
my %DEFAULTS = (
'TicketDatabase' => 'mysql:test_www',
'TicketTable' => 'user_info:user_name:passwd',
'TicketExpires' => 30,
'TicketSecret' => 'http://$ServerName/secret_key.txt',
'TicketDomain' => undef,
);
my %CACHE; # cache objects by their parameters to minimize time-consuming operations
# Set up default parameters by passing in a request object
sub new {
my($class, $r) = @_;
my %self = ();
foreach (keys %DEFAULTS) {
$self{$_} = $r->dir_config($_) || $DEFAULTS{$_};
}
# post-process TicketDatabase and TicketDomain
($self{TicketDomain} = $ServerName) =~ s/^[^.]+//
unless $self{TicketDomain};
# try to return from cache
my $id = join '', sort values %self;
return $CACHE{$id} if $CACHE{$id};
# otherwise create new object
return $CACHE{$id} = bless \%self, $class;
}
# TicketTool::authenticate()
# Call as:
# ($result,$explanation) = $ticketTool->authenticate($user,$passwd)
sub authenticate {
my($self, $user, $passwd) = @_;
my($table, $userfield, $passwdfield) = split ':', $self->{TicketTable};
tie my %DB, 'Tie::DBI', {
'db' => $self->{TicketDatabase},
'table' => $table, 'key' => $userfield,
} or return (undef, "couldn't open database");
return (undef, "invalid account")
unless $DB{$user};
my $saved_passwd = $DB{$user}->{$passwdfield};
return (undef, "password mismatch")
unless $saved_passwd eq crypt($passwd, $saved_passwd);
return (1, '');
}
# TicketTool::fetch_secret()
# Call as:
# $ticketTool->fetch_secret();
sub fetch_secret {
my $self = shift;
unless ($self->{SECRET_KEY}) {
if ($self->{TicketSecret} =~ /^http:/) {
$self->{SECRET_KEY} = LWP::Simple::get($self->{TicketSecret});
} else {
my $fh = Apache::File->new($self->{TicketSecret}) || return undef;
$self->{SECRET_KEY} = <$fh>;
}
}
$self->{SECRET_KEY};
}
# invalidate the cached secret
sub invalidate_secret { undef shift->{SECRET_KEY}; }
# TicketTool::make_ticket()
# Call as:
# $cookie = $ticketTool->make_ticket($r,$username);
#
sub make_ticket {
my($self, $r, $user_name) = @_;
my $ip_address = $r->connection->remote_ip;
my $expires = $self->{TicketExpires};
my $now = time;
my $secret = $self->fetch_secret() or return undef;
my $hash = MD5->hexhash($secret .
MD5->hexhash(join ':', $secret, $ip_address, $now,
$expires, $user_name)
);
return CGI::Cookie->new(-name => 'Ticket',
-path => '/',
-domain => $self->{TicketDomain},
-value => {
'ip' => $ip_address,
'time' => $now,
'user' => $user_name,
'hash' => $hash,
'expires' => $expires,
});
}
# TicketTool::verify_ticket()
# Call as:
# ($result,$msg) = $ticketTool->verify_ticket($r)
sub verify_ticket {
my($self, $r) = @_;
my %cookies = CGI::Cookie->parse($r->header_in('Cookie'));
return (0, 'user has no cookies') unless %cookies;
return (0, 'user has no ticket') unless $cookies{'Ticket'};
my %ticket = $cookies{'Ticket'}->value;
return (0, 'malformed ticket')
unless $ticket{'hash'} && $ticket{'user'} &&
$ticket{'time'} && $ticket{'expires'};
return (0, 'IP address mismatch in ticket')
unless $ticket{'ip'} eq $r->connection->remote_ip;
return (0, 'ticket has expired')
unless (time - $ticket{'time'})/60 < $ticket{'expires'};
my $secret;
return (0, "can't retrieve secret")
unless $secret = $self->fetch_secret;
my $newhash = MD5->hexhash($secret .
MD5->hexhash(join ':', $secret,
@ticket{qw(ip time expires user)})
);
unless ($newhash eq $ticket{'hash'}) {
$self->invalidate_secret; #maybe it's changed?
return (0, 'ticket mismatch');
}
$r->connection->user($ticket{'user'});
return (1, 'ok');
}
# Call as:
# $cookie = $ticketTool->make_return_address($r)
sub make_return_address {
my($self, $r) = @_;
my $uri = Apache::URI->parse($r, $r->uri);
$uri->scheme("http");
$uri->hostname($r->get_server_name);
$uri->port($r->get_server_port);
$uri->query(scalar $r->args);
return CGI::Cookie->new(-name => 'request_uri',
-value => $uri->unparse,
-domain => $self->{TicketDomain},
-path => '/');
}
1;
__END__
Authentication with the Secure Sockets LayerThe Secure Sockets Layer (SSL) is a widely-used protocol for encrypting Internet transmissions. It was originally introduced by Netscape for use with its browser and server products, and has been adapted by the Internet Engineering Task Force (IETF) for use in its standard Transport Layer Security (TLS) protocol.When an SSL-enabled browser talks to an SSL-enabled server, they exchange cryptographic certificates and authenticate each other using secure credentials known as digital certificates. They then set up an encrypted channel with which to exchange information. Everything that the browser sends to the server, including the requested URI, cookies, and the contents of fill-out forms is encrypted, and everything that the server returns to the browser is encrypted as well. For the purposes of authentication and authorization, SSL can be used in two ways. One option is to combine SSL encryption with Basic authentication. The Basic authentication protocol continues to work exactly as described in the previous section, but now the user's password is protected from interception because it is part of the encrypted data stream. This option is simple and doesn't require any code changes. The other option is to use the browser's digital certificate for authorization. The server automatically attempts to authenticates the browser's digital certificate when it first sets up the SSL connection. If it can't, the SSL connection is refused. If you wish, you can use the information provided in the browser's certificate to decide whether this user is authorized to access the requested URI. In addition to the user's name, digital certificates contain a variety of standard fields and any number of optional ones; your code is free to use any of these fields to decide whether the user is authorized. The main advantage of the digital certificate solution is that it eliminates the problems associated with passwords -- users forgetting them or, conversely, choosing ones that are too easy to guess. The main disadvantage is that most users don't use digital certificates. On most of the public Web authentication is one-way only. The server authenticates itself to the browser, but not vice-versa. Therefore authentication by digital certificate is only suitable in intranet environments where the company issues certificates to its employees as a condition of their accessing internal Web servers. There are several SSL-enabled versions of Apache, and there will probably be more in the future. The current list follows. Each offers a different combination of price, features and support. Open-source (free) versions:
Using Digital Certificates for AuthorizationThe SSL protocol does most of its work at a level beneath the workings of the HTTP protocol. The exchange and verificaton of digital certificates and the establishment of the encrypted channel all occur before any of Apache's handlers run. For this reason, authorization based on the contents of a digital certificate looks quite different from the other examples we've seen in this chapter. Furthermore, the details of authorization vary slightly among the different implementations of ApacheSSL. This section describes the way it works in Ralf S.Engelschall's mod_ssl. If you are using a different version of ApacheSSL, you should check your vendor's documentation for differences.The text representation of a typical client certificate is shown in Listing 6.15. It consists of a ``Subject'' section, which gives information on the person to whom the certificate is issued, and a ``Certificate'' section, which gives information about the certificate itself. Within the Subject section are a series of tag=value pairs. There can be an arbitrary number of such pairs, but several are standard and can be found in any certificate:
CN User's common name EMail User's e-mail address O User's organization (employer) OU Organizational unit (e.g. department) L User's locality, usually a city or town SP User's state or province C User's country code The user's distinguished name (DN) is a long string consisting of the concatenation of each of these fields in the following format:
/C=US/SP=MA/L=Boston/O=Capricorn Organization/OU=Sales/CN=Wanda/[email protected] European users will recognize the footprints of the OSI standards committee here. The DN is guaranteed to be unique among all the certificates issued by a particular certificate-granting authority. The Certificate section contains the certificate's unique serial number and other data, followed by more tag=value pairs giving information about the organization issuing the certificate. The standard fields are the same as those described for the Subject. This is followed by a Validity period, which gives the span of time that the certificate should be considered valid. You are free to use any of these fields for authorization. You can authorize based on the user's CN field, on the certificate's serial number, on the validity period, or on any of the Subject or Issuer tags.
The certificate information is actually stored in a compact binary form
rather than the text form shown here. When the connection is established,
the SSL library parses out the certificate fields and stores them in a
private data structure. During the fixup phase, these fields are turned into various environment variables with
names like
Subject: C=US SP=MA L=Boston O=Capricorn Organization OU=Sales CN=Wanda [email protected]
Certificate: Data: Version: 1 (0x0) Serial Number: 866229881 (0x33a19e79) Signature Algorithm: md5WithRSAEncryption Issuer: C=US SP=MA L=Boston O=Capricorn Consulting OU=Security Services CN=Capricorn Signing Services Root CA [email protected] Validity: Not Before: Jun 13 19:24:41 1998 GMT Not After : Jun 13 19:24:41 1999 GMT The most straightforward way to authenticate based on certificate information is to take advantage of the SSLRequire access control directive. In mod_ssl, such a directive might look like this:
<Location /certified>
SSLRequire %{SSL_CLIENT_S_DN_CN} in ("Wanda Henderson","Joe Bloe") \
and %{REMOTE_ADDR} =~ m/^192\.128\.3\.[0-9]+$/
</Location>
This requires that the CN tag of the DN field of the Subject section of the certificate match either ``Wanda Henderson'' or ``Joe Bloe'', and that the browser's IP address satisfy a pattern match placing it within the 192.128.3 subnetwork. mod_ssl has a rich language for querying the contents of the client certificate. See its documentation for the details. Other ApacheSSL implementations also support operations similar to SSLRequire, but they differ somewhat in detail. Note that to Apache, SSLRequire is an access control operation rather than an authentication/authorization operation. This is because no action on the part of the user is needed to gain access -- his browser either has the right certificate, or it doesn't. A slightly more involved technique for combining certificate information with user authorization is to take advantage of the the FakeBasicAuth option of the SSLOptions directive. When this option is enabled, mod_ssl installs an authentication handler that retrieves the DN from the certificate. The handler synthesizes the DN along with a hard-coded password consisting of the string ``password'', into the Basic base64 encoded format, stuffs it into the incoming Authorization header field and returns DECLINED. In effect this fakes the ordinary Basic authentication process by making it seem as if the user provided a username and password pair. The DN is now available for use by downstream authentication and authorization modules. However, using FakeBasicAuth means that mod_ssl must be the first authentication handler run for the request and that an authentication handler further down the chain must be able to authenticate using the client's DN. It is much simpler to bypass all authentication handlers altogether and get a hold of the DN by using a subrequest. As an example, we'll show a simple authorization module named Apache::AuthzSSL which checks that a named field of the DN name matches that given in one or more require directives. A typical configuration section will look like this:
SSLVerifyClient require SSLVerifyDepth 2 SSLCACertificateFile conf/ssl.crt/ca-bundle.crt <Directory /usr/local/apache/htdocs/ID/please> SSLRequireSSL AuthName SSL AuthType Basic PerlAuthenHandler Apache::OK PerlAuthzHandler Apache::AuthzSSL require C US require O "Capricorn Organization" require OU Sales Marketing </Directory> The SSLVerifyClient directive, which must be present in the main part of the configuration file, requires that browsers must present certificates. The SSLVerifyDepth and SSLCACertificateFile directives are used to configure how deeply mod_ssl should verify client certificates, see the mod_ssl documentation for details. The SSLRequireSSL directive requires that SSL be active in order to access the contents of this directory. AuthName and AuthType are not required, since we are not peforming Basic authentication, but we put them in place anyhow just in case, as some modules might complain without them. Since the password is invariant when client certificate verification is in use, we bypass password checking by installing Apache::OK as the authentication handler for this directory.* We then install Apache::AuthzSSL as the authorization handler and give it three different require statements to satisfy. We require that the Country field equal ``US'', the Organization field equal ``Capricorn Organization'', and the Organizational Unit be one of ``Sales'' or ``Marketing''. Listing 6.16 gives the code for Apache::AuthzSSL. It brings in in Apache::Constants and the quotewords() text parsing function from the standard Text::ParseWords module. It recovers the request object, and calls its requires() method to retrieve the list of authorization requirements that are in effect. The handler then issues a subrequest to retrieve the certificate's DN, which is added to the subprocess_env table during the fixup stage by mod_ssl. Notice early on, the handler returns OK if is_main() returns true, to avoid authorization checks during the subrequest. Once the DN is recovered, it is split into its individual fields using a pattern match operation.
Now the routine loops through each of the requirements, breaking them into
a DN field name and a list of possible values, each of which it checks in
turn. If none of the specified values matches the DN, we log an error and
return a
|
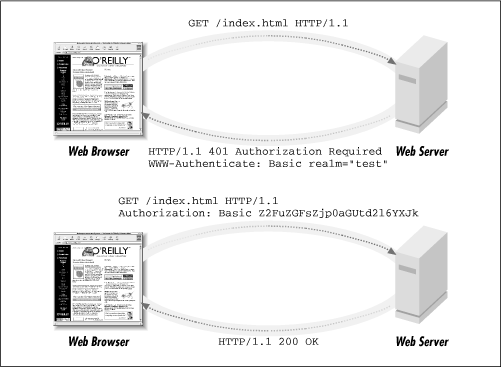
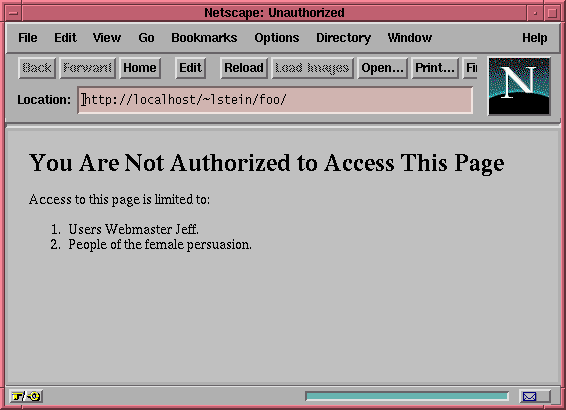
|
|