| ISO 9000 | ISO 14000 |
GMP Consulting |
Chapter 7: Other Request PhasesThe previous chapters have taken you on a wide-ranging tour of the most popular and useful areas of the Apache API. But we're not done yet! The Apache API allows you to customize URI translation, logging, the handling of proxy transactions, and the manner in which HTTP headers are parsed. There's even a way to incorporate snippets of Perl code directly into HTML pages that use server-side includes.We've already shown you how to customize the response, authentication, authorization, and access control phases of the Apache request cycle. Now we'll fill in the cracks. At the end of the chapter, we show you the Perl server-side include system, and demonstrate a technique for extending the Apache Perl API by subclassing the Apache request object itself.
The Child Initialization and Exit PhasesApache provides hooks into the child process initialization and exit handling. The child process initialization handler, installed with PerlChildInitHandler is called just after the main server forks off a child but before the child has processed any incoming requests. The child exit handler, installed with PerlChildExitHandler, is called just before the child process is destroyed.You might need to install handlers for these phases in order to perform some sort of module initialization that won't survive a fork. For example, the Apache::DBI module has a child init handler that initializes a cache of per-child database connections, and the Apache::Resource module steps in during this phase to set up resource limits on the child processes. The latter is configured in this way:
PerlChildInitHandler Apache::Resource Like other handlers, you can install a child init handler programatically using Apache::push_handlers(). However, because the child init phase comes so early, the only practical place to do this is from within the parent process, in a Perl startup file configured with a PerlModule or PerlRequire directive. For example, here's how to install an anonymous subroutine that will execute during child initialization to choose a truly random seed value for Perl's random number generator:
use Math::TrulyRandom ();
Apache->push_handlers(PerlChildInitHandler => sub {
srand Math::TrulyRandom::truly_random_value();
});
Install this piece of code in the Perl startup file. By changing the value of the random number seed on a per-child basis, it ensures that each child process produces a different sequence of random numbers when the built in rand() function is called. The child exit phase complements the child intialization phase. Child processes may exit for various reasons: the MaxRequestsPerChild limit may have been reached, the parent server was shutdown, or a fatal error occurred. This phase gives modules a chance to tidy up after themselves before the process exits. The most straightforward way to install a child exit handler is with the explicit PerlChildExitHandler directive, as in:
PerlChildExitHandler Apache::Guillotine During the child exit phase, mod_perl invokes the Perl API function, perl_destruct()* to run the contents of END blocks and to invoke the DESTROY method for any global objects that have not gone out of scope already. Refer to the Chapter 9 section Special Global Variables, Subroutines and Literals for details. Note: neither child initialization nor exit hooks are available on Win32 platforms for the reason that the Win32 port of Apache uses a single process.
The Post Read Request PhaseWhen a listening server receives an incoming request, it reads the HTTP request line and parses any HTTP headers sent along with it. Provided that what's been read is valid HTTP, Apache gives modules an early chance to step in during the post_read_request phase, known to the Perl API world as the PerlPostReadRequestHandler. This is the very first callback that Apache makes when serving an HTTP request, and it happens even before URI translation turns the requested URI into a physical pathname.The post_read_request phase is a handy place to initialize per-request data that will be available to other handlers in the request chain. Because of its usefulness as an initialize routine, mod_perl provides the directive PerlInitHandler as a more readable alias to PerlPostReadRequestHandler. Since the post_read_request phase happens before URI translation, PerlPostReadRequestHandler cannot appear in <Location>, <Directory> or <Files> sections. However the PerlInitHandler directive is actually a bit special. When it appears outside a directory section, it acts as an alias for PerlPostReadRequestHandler as just described. However, when it appears within a directory section, it acts as an alias for PerlHeaderParserHandler (discussed later in this chapter), allowing for per-directory initialization. In other words, wherever you put PerlInitHandler, it will act the way you expect.
Several optional Apache modules install handlers for the
post_read_request phase. For example, the mod_unique_id module steps in here to create the UNIQUE_ID environment variable. When the module is activated, this variable is unique
to each request over an extended period of time, and so is useful for
logging and the generation of session IDs (see Chapter 5). Perl scripts can
get at the value of this variable by reading
mod_setenvif also steps in during this phase to allow you to set enviroment variables
based on the incoming client headers. For example, this directive will set
the environment variable
SetEnvIf Referer \.acme\.com LOCAL_REFERRAL mod_perl itself uses the post_read_request phase to process the PerlPassEnv and PerlSetEnv directives, allowing environment variables to be passed to modules that execute early in the request cycle. The built-in Apache equivalents, PassEnv and SetEnv don't get processed until the fixup phase, which may be too late. The Apache::StatINC module, which watches .pm files for changes and reloads them if necessary, is also usually installed into this phase:
PerlPostReadRequestHandler Apache::StatINC PerlInitHandler Apache::StatINC # same thing, but easier to type
The URI Translation PhaseOne of the Web's virtues is its Uniform Resource Identifier (URI) and Uniform Resource Locator (URL) standards.* End users never know for sure what is sitting behind a URI. It could be a static file, a dynamic script, a proxied request, or something even more esoteric. The file or program behind a URI may change over time, but this too is transparent to the end user.
DECLINED) terminates the phase. This prevents several URI translators from
interfering with one another by trying to map the same URI onto several
different file paths.
By default, two URI translation handlers are installed in stock Apache distributions. The mod_alias module looks for the existence of several directives that may apply to the current URI. These include Alias, ScriptAlias, Redirect, AliasMatch, and other directives. If it finds one, it uses the directive's value to map the URI to a file or directory somewhere on the server's physical file system. Otherwise, the request falls through to the http_core module (where the default response handler is also found). http_core simply appends the URI to the value of the DocumentRoot configuration directive, forming a file path relative to the document root. The optional mod_rewrite module implements a much more comprehensive URI translator that allows you to slice and dice URIs in various interesting ways. It is extremely powerful, but uses a series of pattern matching conditions and substitution rules that can be difficult to get right. Once a translation handler has done its work, Apache walks along the returned filename path in the manner described in Chapter 4, finding where the path part of the URI ends and the additional path information begins. This phase of processing is performed internally and cannot be modified by the module API. In addition to their intended role in transforming URIs, translation handlers are sometimes used to associate certain types of URIs with specific upstream handlers. We'll see examples of this later in this chapter when we discuss creating custom proxy services.
A Very Simple Translation HandlerLet's look at an example. Many of the documents browsed on a web site are files that are located under the configured DocumentRoot. That is, the requested URI is a filename relative to a directory on the hard disk. Just so you can see how simple a translation handler's job can be, we present a Perl version of Apache's default translation handler found in the http_core module.
package Apache::DefaultTrans;
use Apache::Constants qw(:common BAD_REQUEST); use Apache::Log ();
sub handler {
my $r = shift;
my $uri = $r->uri;
if($uri !~ m:^/: or index($uri, '*')) {
$r->log->error("Invalid URI in request ", $r->the_request);
return BAD_REQUEST;
}
$r->filename($r->document_root . $r->uri);
return OK; }
1; __END__
The handler begins by subjecting the requested URI to a few sanity checks,
making sure that it begins with a slash and doesn't contain any ``*''
characters. If the URI fails these tests, we log an error message and
return We don't check at this point whether the file exists or can be opened. This is the job of handlers further down the request chain. To install this handler, just add the following directive to the main part of your perl.conf configuration file (or any other Apache configuration file, if you prefer):
PerlTransHandler Apache::DefaultTrans Beware. You probably won't want to keep this handler installed for long. Because it overrides other translation handlers, you'll lose the use of Alias, ScriptAlias and other standard directives.
A Practical Translation HandlerHere's a slightly more complex example. Consider a Web-based system for archiving software binaries and source code. On a nightly basis an automated system will copy changed and new files from a master repository to multiple mirror sites. Because of the vagaries of the Internet, it's important to confirm that the entire file, and not just a fragment of it, is copied from one mirror site to the other.One technique for solving this problem would be to create an MD5 checksum for each file and store the information on the repository. After the mirror site copies the file, it checksums the file and compares it against the master checksum retrieved from the repository. If the two values match, then the integrity of the copied file is confirmed. In this section, we'll begin a simple system to retrieve precomputed MD5 checksums from an archive of files. To retrieve the checksum for a file, you simply append the extension .cksm to the end of its URL. For example, if the archived file you wish to retrieve is:
/archive/software/cookie_cutter.tar.gz then you can retrieve a text file containing its MD5 checksum by fetching this URL:
/archive/software/cookie_cutter.tar.gz.cksm The checksum files will be precomputed and stored in a directory tree that parallels the document hierarchy. For example, if the document itself is physically stored in:
/home/httpd/htdocs/archive/software/cookie_cutter.tar.gz then its checksum will be stored in a parallel tree in a file named:
/home/httpd/checksums/archive/software/cookie_cutter.tar.gz The URI translation handler's job is to map requests for /file/path/filename.cksm files into the physical file /home/httpd/checksums/file/path/filename. When used from a browser, the results look something like the screenshot in Figure 7.1. As often happens with Perl programs, the problem takes longer to state than to solve. Listing 7.1 shows a translation handler, Apache::Checksum1 that accomplishes this task. The structure is similar to other Apache Perl modules. After the usual preamble, the handler() subroutine shifts the Apache request object off the call stack and uses it to recover the URI of the current request, which is stashed in the local variable $uri. The subroutine next looks for a configuration directive named ChecksumDir which defines the top of the tree where the checksums are to be found. If
defined,
handler() stores the value in a local named $cksumdir. Otherwise, it assumes a default value defined in DEFAULT_CHECKSUM_DIR.
Now the subroutine checks whether this URI needs special handling. It does
this by attempting a string substitution which will replace the
.cksm URI with a physical path to the corresponding file in the checksums
directory tree. If the substitution returns a false value, then the
requested URI does not end with the .cksm extension and we return
package Apache::Checksum1; # file: Apache/Checksum1.pm use strict; use Apache::Constants qw(:common); use constant DEFAULT_CHECKSUM_DIR => '/usr/tmp/checksums';
sub handler {
my $r = shift;
my $uri = $r->uri;
my $cksumdir = $r->dir_config('ChecksumDir') || DEFAULT_CHECKSUM_DIR;
$cksumdir = $r->server_root_relative($cksumdir);
return DECLINED unless $uri =~ s!^(.+)\.cksm$!$cksumdir$1!;
$r->filename($uri);
return OK;
}
1; __END__ The configuration for this translation handler should look something like this:
# checksum translation handler directives PerlTransHandler Apache::Checksum1 PerlSetVar ChecksumDir /home/httpd/checksums <Directory /home/httpd/checksums> ForceType text/plain </Directory> This configuration declares a URI translation handler with the PerlTransHandler directive, and sets the Perl configuration variable ChecksumDir to /home/httpd/checksums, the top of the checksum tree. We also need a <Directory> section to force all files in the checksums directory to be of type text/plain. Otherwise, the default MIME type checker will try to use each checksum file's extension to determine its MIME type. There are a couple of important points about this configuration section. First, the PerlTransHandler and PerlSetVar directives are located in the main section of the configuration file, not in a <Directory>, <Location> or <Files> section. This is because URI translation phase runs very early in the request processing cycle, before Apache has a definite URI or filepath to use in selecting an appropriate <Directory> <Location> or <Files> section to take its configuration from. For the same reason, PerlTransHandler is not allowed in .htaccess files, although you can use it in virtual host sections. The second point is that the ForceType directive is located in a <Directory> section rather than in a <Location> block. The reason for this is that the <Location> section refers to the requested URI, which is not changed by this particular translation handler. To apply access control rules and other options to the physical file path returned by the translation handler, we must use <Directory> or <Files>. To set up the checksum tree, you'll have to write a script that will recurse through the Web document hierarchy (or a portion of it), and create a mirror directory of checksum files. In case you're interested in implementing a system like this one, Listing 7.2 gives a short script named checksum.pl that does this. It uses the File::Find module to walk the tree of source files, the MD5 module to generate MD5 checksums, and File::Path and File::Basename for filename manipulations. New checksum files are only created if the checksum file doesn't exist or the modification time of the source file is more recent than that of an existing checksum file. You call the scriptlike this:
% checksum.pl -source ~www/htdocs -dest ~www/checksums Replace ~www/htdocs and ~www/checksums with the paths to the Web document tree and the checksums directory on your system.
#!/usr/local/bin/perl
use File::Find; use File::Path; use File::Basename; use IO::File; use MD5; use Getopt::Long; use strict; use vars qw($SOURCE $DESTINATION $MD5);
GetOptions('source=s' => \$SOURCE,
'destination=s' => \$DESTINATION) || die <<USAGE;
Usage: $0
Create a checksum tree.
Options:
-source <path> File tree to traverse [.]
-destination <path> Destination for checksum tree [TMPDIR]
Option names may be abbreviated.
USAGE
$SOURCE ||= '.';
$DESTINATION ||= $ENV{TMPDIR} || '/tmp';
die "Must specify absolute destination directory" unless $DESTINATION=~m!^/!;
$MD5 = new MD5;
find(\&wanted,$SOURCE);
# This routine is called for each node (directory or file) in the
# source tree. On entry, $_ contains the filename,
# and $File::Find::name contains its full path.
sub wanted {
return unless -f $_ && -r _;
my $modtime = (stat _)[9];
my ($source,$dest,$url);
$source = $File::Find::name;
($dest = $source)=~s/^$SOURCE/$DESTINATION/o;
return if -e $dest && $modtime <= (stat $dest)[9];
($url = $source) =~s/^$SOURCE//o;
make_checksum($_,$dest,$url);
}
# This routine is called with the source file, the destination in which
# to write the checksum, and a URL to attach as a comment to the checksum.
sub make_checksum {
my ($source,$dest,$url) = @_;
my $sfile = IO::File->new($source) || die "Couldn't open $source: $!\n";
mkpath dirname($dest); # create the intermediate directories
my $dfile = IO::File->new(">$dest") || die "Couldn't open $dest: $!\n";
$MD5->reset;
$MD5->addfile($sfile);
print $dfile $MD5->hexdigest(),"\t$url\n"; # write the checksum
}
__END__
Using a Translation Handler to Change the URIInstead of completely translating a URI into a filename, a translation handler can modify the URI itself and let other handlers do the work of completing the translation into a physical path. This is very useful because it allows the handler to interoperate with other URI translation directives such as Alias and UserDir.To change the URI, your translation handler should set it with the Apache request object's uri() method instead of (or in addition to) the filename() method: $r->uri($new_uri);
After changing the URI, your handler should then return Listing 7.3 shows a reworked version of the checksum translation handler that alters the URI rather than sets the filename directly. The code is nearly identical to the first version of this module, but instead of retrieving a physical directory path from a PerlSetVar configuration variable named ChecksumDir, the handler looks for a variable named ChecksumPath which is expected to contain the virtual (URI space) directory in which the checksums can be found. If the variable isn't defined, then /checksums is assumed. We perform the string substitution on the requested URI as before. If the substitution succeeds, we write the modified URI back into the request record by calling the request object's uri() method. We then return DECLINED so that Apache will pass the altered request on to other translation handlers.
package Apache::Checksum2; # file: Apache/Checksum2.pm use strict; use Apache::Constants qw(:common); use constant DEFAULT_CHECKSUM_PATH => '/checksums';
sub handler {
my $r = shift;
my $uri = $r->uri;
my $cksumpath = $r->dir_config('ChecksumPath') || DEFAULT_CHECKSUM_PATH;
return DECLINED unless $uri =~ s!^(.+)\.cksm$!$cksumpath$1!;
$r->uri($uri);
return DECLINED;
}
1; __END__ The configuration file entries needed to work with Apache::Checksum2 are shown below. Instead of passing the translation handler a physical path in the ChecksumDir variable, we use ChecksumPath to pass a virtual URI path. The actual translation from a URI to a physical path is done by the standard mod_alias module from information provided by an Alias directive. Another point to notice is that because the translation handler changed the URI, we can now use a <Location> section to force the type of the checksum files to text/plain.
PerlTransHandler Apache::Checksum2 PerlSetVar ChecksumPath /checksums Alias /checksums/ /home/www/checksums/ <Location /checksums> ForceType text/plain </Location> In addition to interoperating well with other translation directives, this version of the checksum translation handler deals correctly with the implicit retrieval of index.html files when the URI ends in a directory name. For example, retrieving the partial URI /archive/software/.cksm will be correctly transformed into a request for /home/httpd/checksums/archive/software/index.html. On the downside, this version of the translation module may issue potentially confusing error messages if a checksum file is missing. For example, if the user requests URI /archive/software/index.html.cksm and the checksum file is not present, Apache's default ``Not Found'' error message will read ``The requested URL /checksums/archive/software/index.html was not found on this server.'' The user may be confused to see an error message refers to a different URI than the one he requested. Another example of altering the URI on the fly can be found in Chapter 5, where we used a translation handler to manage session IDs embedded in URIs. This handler copies the session ID from the URI into an environment variable for later use by the content handler, then strips the session ID from the URI and writes it back into the request record.
Installing a Custom Response Handler in the URI Translation PhaseIn addition to its official use as the place to modify the URI and/or filename of the requested document, the translation phase is also a convenient place to set up custom content handlers for particular URIs. To continue with our checksum example, let's generate the checksum from the requested file on the fly rather than using a precomputed value. This eliminates the need to maintain a parallel directory of checksum files, but adds the cost of additional CPU cycles every time a checksum is requested.Listing 7.4 shows Apache::Checksum3. It's a little longer than the previous examples, so we'll step through it a chunk at a time.
package Apache::Checksum3; # file: Apache/Checksum3.pm use strict; use Apache::Constants qw(:common); use Apache::File (); use MD5 ();
my $MD5 = MD5->new; Because this module is going to produce the MD5 checksums itself, we bring in the Apache::File and MD5 modules. We then create a file-scoped lexical MD5 object that will be used within the package to generate the MD5 checksums of requested files.
sub handler {
my $r = shift;
my $uri = $r->uri;
return DECLINED unless $uri =~ s/\.cksm$//;
$r->uri($uri);
We now define two subroutines. The first, named handler() is responsible for the translation phase of the request. Like its predecessors, this subroutine recovers the URI from the request object and looks for the telltale .cksm extension. However, instead of constructing a new path that points into the checksums directory, we simply strip off the extension and write the modified path back into the request record.
$r->handler("perl-script");
$r->push_handlers(PerlHandler => \&checksum_handler);
return DECLINED;
}
Now the interesting part begins. We set the request's content handler to
point to the second subroutine in the module,
checksum_handler(). This is done in two phases. First we call
Apache will now proceed as usual through the authorization, authentication, MIME type checking, and fixup phases until it gets to the content phase, at which point our Apache::Checksum3 will be reentered through the checksum_handler() routine:
sub checksum_handler {
my $r = shift;
my $file = $r->filename;
my $sfile = Apache::File->new($file) || return DECLINED;
$r->content_type('text/plain');
$r->send_http_header;
return OK if $r->header_only;
$MD5->reset;
$MD5->addfile($sfile);
$r->print($MD5->hexdigest(),"\t",$r->uri,"\n");
return OK;
}
Like the various content handlers we saw in Chapter 4,
checksum_handler() calls the request object's filename() method to retrieve the physical filename and attempts to open it, returning
Because this module is entirely self-contained, it has the simplest configuration of them all:
PerlTransHandler Apache::Checksum3 Like other PerlTransHandler directives, this one must be located in the main part of the configuration file or in a virtual host section.
package Apache::Checksum3;
# file: Apache/Checksum3.pm
use strict;
use Apache::Constants qw(:common);
use Apache::File ();
use MD5 ();
my $MD5 = MD5->new;
sub handler {
my $r = shift;
my $uri = $r->uri;
return DECLINED unless $uri =~ s/\.cksm$//;
$r->uri($uri);
$r->handler("perl-script");
$r->push_handlers(PerlHandler => \&checksum_handler);
return DECLINED;
}
sub checksum_handler {
my $r = shift;
my $file = $r->filename;
my $sfile = Apache::File->new($file) || return DECLINED;
$r->content_type('text/plain');
$r->send_http_header;
return OK if $r->header_only;
$MD5->reset;
$MD5->addfile($sfile);
$r->print($MD5->hexdigest(),"\t",$r->uri,"\n");
return OK;
}
1;
__END__
Don't think that you must always write a custom translation handler in order to gain control over the URI translation phase. The powerful mod_rewrite module gives you great power to customize this phase. For example, by adding a mod_rewrite RewriteRule directive, you can define a substitution rule that transforms requests for .cksm URIs into requests for files in the checksum directory, doing in a single line what our first example of a translation handler did in 17.
The Header Parser PhaseAfter Apache has translated the URI into a filename, it enters the header parser phase. This phase gives handlers a chance to examine the incoming request header and to take special action, perhaps altering the headers on the fly (as we will do below to create an anonymous proxy server), or blocking unwanted transactions at an early stage. For example, the header parser phase is commonly used to block unwanted robots before they consume the server resources during the later phases. You could use the Apache::BlockAgent module, implemented as an access handler in the last chapter, to block robots during this earlier phase.
Header parser handlers are installed with the
PerlHeaderParserHandler. Because the URI has been mapped to a filename at this point, the
directive is allowed in .htaccess files and directory configuration sections, as well as in the main body of
the configuration files. All registered header parser handlers will be run
unless one returns an error code or When PerlInitHandler is used within a directory section or a .htaccess file, it acts as an alias to PerlHeaderParserHeader.
Implementing an Unsupported HTTP MethodOne non-trivial use for the header parser phase is to implement an unsupported HTTP request method. The Apache server handles the most common HTTP methods, such as GET, HEAD and POST. Apache also provides hooks for managing the less commonly used PUT and DELETE methods, but the work of processing the method is left to third-party modules to implement. In addition to these methods, there are certain methods that are part of the HTTP/1.1 draft that are not supported by Apache at this time. One such method is PATCH*, which is used to change the contents of a document on the server side by applying to it a ``diff'' file provided by the client.
If you've never worked with patch files, you'll be surprised at how insanely useful they are. Say you have two versions of a large file, an older version named file.1.html and a newer version named file.2.html. You can use the diff command to compute the difference between the two, like this:
% diff file.1.html file.2.html > file.diff When diff is finished, the output file.diff file will contain only the lines that have changed between the two files, along with information indicating the positions of the changed lines in the files. You can examine a ``diff'' file in a text editor to see how the two files differ. More interestingly, however, you can use Larry Wall's patch program to apply the diff to file.1.html, transforming it in into a new file identical to file.2.html. Patch is simple to use:
% patch file.1.html < file.diff Because two versions of the same file tend to be more similar than they are different, diff files are usually short, making it much more efficient to send the diff file around than the entire new version. This is the rationale for the HTTP/1.1 PATCH method. It complements PUT, which is used to transmit a whole new document to the server, by sending what should be changed between an existing document and a new one. When a client requests a document with the PATCH method, the URL it provides corresponds to the file to be patched, and the request's content is the diff file to be applied. Listing 7.5 gives the code for the PATCH handler, appropriately named Apache::PATCH. It defines both the server-side routines for accepting PATCH documents, and a small client-side program to use for submitting patch files to the server.
package Apache::PATCH; # file: Apache/PATCH.pm use strict; use vars qw($VERSION @EXPORT @ISA); use Apache::Constants qw(:common BAD_REQUEST); use Apache::File (); use File::Basename 'dirname'; @ISA = qw(Exporter); @EXPORT = qw(PATCH); $VERSION = '1.00'; use constant PATCH_TYPE => 'application/diff'; my $PATCH_CMD = "/usr/local/bin/patch"; We begin by pulling in required modules, including Apache::File and File::Basename. We also bring in the Exporter module. This is not used by the server-side routines, but is needed by the client-side library to export the PATCH() subroutine. We now declare some constants, including a MIME type for the submitted patch files, the location of the patch program on our system, and two constants that will be used to create temporary scratch files. The main entry point to server-side routines is through a header parsing phase handler named handler(). It detects whether the request uses the PATCH method, and if so, installs a custom response handler to deal with it. This means we can install the patch routines with this configuration directive:
PerlHeaderParserHandler Apache::PATCH The rationale for installing the patch handler with the PerlHeaderParserHandler directive rather than PerlTransHandler is that we can use the former directive within directory sections and .htaccess files, allowing us to make the PATCH method active only for certain parts of the document tree. The definition of handler() is simple. :
sub handler {
my $r = shift;
return DECLINED unless $r->method eq 'PATCH';
unless ($r->some_auth_required) {
$r->log_reason("Apache::PATCH requires access control");
return FORBIDDEN;
}
$r->handler("perl-script");
$r->push_handlers(PerlHandler => \&patch_handler);
return OK;
}
We recover the request object and call method() to determine whether the request method equals ``PATCH''. If not, we decline the transaction. Next we perform a simple but important security check. We call some_auth_required() to determine whether the requested URI is under password protection. If the document is not protected, we log an error and return a result code of FORBIDDEN. This is a hard-wired insurance that the file to be patched is protected in some way using any of the many authentication modules available to Apache (see Chapter 6 for a few). If the request passes the checks, we adjust the content handler to be the patch_handler() subroutine by calling the request object's handler() and push_handlers() methods. This done, we return OK, allowing other installed header parsers to process the request. The true work of the module is done in the patch_handler() subroutine, which is called during the response phase:
sub patch_handler {
my $r = shift;
return BAD_REQUEST
unless lc($r->header_in("Content-type")) eq PATCH_TYPE;
This subroutine recovers the request object and immediately checks the content type of the submitted data. Unless the submitted data has MIME type application/diff, indicating a diff file, we return a result code of BAD_REQUEST.
# get file to patch
my $filename = $r->filename;
my $dirname = dirname($filename);
my $reason;
do {
-e $r->finfo or $reason = "$filename does not exist", last;
-w _ or $reason = "$filename is not writable", last;
-w $dirname or $reason = "$filename directory is not writable", last;
};
if ($reason) {
$r->log_reason($reason);
return FORBIDDEN;
}
Next we check whether the patch operation is likely to succeed. In order for the patch program to work properly, both the file to be patched and the directory that contains it must be writable by the current process.* This is because patch creates a temporary file while processing the diff and renames it when it has successfully completed its task. We recover the filename corresponding to the request, and the name of the directory that contains it. We then subject the two to a series of file tests. If any of the tests fails, we log the error and return FORBIDDEN.
# get patch data
my $patch;
$r->read($patch, $r->header_in("Content-length"));
# new temporary file to hold output of patch command
my($tmpname, $patch_out) = Apache::File->tmpfile;
unless($patch_out) {
$r->log_reason("can't create temporary output file: $!");
return FORBIDDEN;
}
The next job is to retrieve the patch data from the request. We do this
using the request object's read() method to copy
Content-length bytes of patch data from the request to a local variable named $patch. We
are about to call the patch command, but before we do so we must arrange
for its output (both standard output and standard error) to be saved to a
temporary file so that we can relay the output to the user. We call the Apache::File method
tmpfile() to return a unique temporary filename. We store the temporary file's name
and handle into variables named
# redirect child processes stdout and stderr to temporary file open STDOUT, ">&=" . fileno($patch_out); We want the output from patch to go to the temporary file rather than to standard output (which was closed by the parent server long, long ago). So we reopen STDOUT, using the ``>&='' notation to open it on the same file descriptor as $patch_out.* See the description of open() in the perlfunc manual page for a more detailed description of this facility.
# open a pipe to the patch command
local $ENV{PATH}; #keep -T happy
my $patch_in = Apache::File->new("| $PATCH_CMD $filename 2>&1");
unless ($patch_in) {
$r->log_reason("can't open pipe to $PATCH_CMD: $!");
return FORBIDDEN;
}
At this point we open up a pipe to the patch command and store the pipe in a new filehandle named $patch_in. We call patch with a single command-line argument, the name of the file to change stored in $filename. The piped open command also uses the ``2>&1'' notation, which is the Bourne shell's arcane way of indicating that standard error should be redirected to the same place that standard output is directed, which in this case is to the temporary file. If we can't open the pipe for some reason, we log the error and exit.
# write data to the patch command print $patch_in $patch; close $patch_in; close $patch_out; We now print the diff file to the patch pipe. patch will process the diff file, and write its output to the temporary file. After printing, we close the command pipe and the temporary filehandle.
$patch_out = Apache::File->new($tmpname);
# send the result to the user
$r->send_http_header("text/plain");
$r->send_fd($patch_out);
close $patch_out;
return OK;
}
The last task is to send the patch output back to the client. We send the HTTP header, using the convenience form that allows us to set the MIME type in a single step. We now send the contents of the temporary file using the request method's send_fd() method. Our work done, we close the temporary filehandle and return OK.*
package Apache::PATCH;
# file: Apache/PATCH.pm
use strict;
use vars qw($VERSION @EXPORT @ISA);
use Apache::Constants qw(:common BAD_REQUEST);
use Apache::File ();
use File::Basename 'dirname';
@ISA = qw(Exporter);
@EXPORT = qw(PATCH);
$VERSION = '1.00';
use constant PATCH_TYPE => 'application/diff';
my $PATCH_CMD = "/usr/local/bin/patch";
sub handler {
my $r = shift;
return DECLINED unless $r->method eq 'PATCH';
unless ($r->some_auth_required) {
$r->log_reason("Apache::PATCH requires access control");
return FORBIDDEN;
}
$r->handler("perl-script");
$r->push_handlers(PerlHandler => \&patch_handler);
return OK;
}
sub patch_handler {
my $r = shift;
return BAD_REQUEST
unless lc($r->header_in("Content-type")) eq PATCH_TYPE;
# get file to patch
my $filename = $r->filename;
my $dirname = dirname($filename);
my $reason;
do {
-e $r->finfo or $reason = "$filename does not exist", last;
-w _ or $reason = "$filename is not writable", last;
-w $dirname or $reason = "$filename directory is not writable", last;
};
if ($reason) {
$r->log_reason($reason);
return FORBIDDEN;
}
# get patch data
my $patch;
$r->read($patch, $r->header_in("Content-length"));
# new temporary file to hold output of patch command
my($tmpname, $patch_out) = Apache::File->tmpfile;
unless($patch_out) {
$r->log_reason("can't create temporary output file: $!");
return FORBIDDEN;
}
# redirect child processes stdout and stderr to temporary file
open STDOUT, ">&=" . fileno($patch_out);
# open a pipe to the patch command
local $ENV{PATH}; #keep -T happy
my $patch_in = Apache::File->new("| $PATCH_CMD $filename 2>&1");
unless ($patch_in) {
$r->log_reason("can't open pipe to $PATCH_CMD: $!");
return FORBIDDEN;
}
# write data to the patch command
print $patch_in $patch;
close $patch_in;
close $patch_out;
$patch_out = Apache::File->new($tmpname);
# send the result to the user
$r->send_http_header("text/plain");
$r->send_fd($patch_out);
close $patch_out;
return OK;
}
# This part is for command-line invocation only.
my $opt_C;
sub PATCH {
require LWP::UserAgent;
@Apache::PATCH::ISA = qw(LWP::UserAgent);
my $ua = __PACKAGE__->new;
my $url;
my $args = @_ ? \@_ : \@ARGV;
while (my $arg = shift @$args) {
$opt_C = shift @$args, next if $arg eq "-C";
$url = $arg;
}
my $req = HTTP::Request->new('PATCH' => $url);
my $patch = join '', <STDIN>;
$req->content(\$patch);
$req->header('Content-length' => length $patch);
$req->header('Content-type' => PATCH_TYPE);
my $res = $ua->request($req);
if($res->is_success) {
print $res->content;
}
else {
print $res->as_string;
}
}
sub get_basic_credentials {
my($self, $realm, $uri) = @_;
return split ':', $opt_C, 2;
}
1;
__END__
At the time this chapter was written, no Web browser or publishing system had actually implemented the PATCH method. The remainder of the listing contains code for implementing a PATCH client. You can use this code from the command line to send patch files to servers that have the PATCH handler installed and watch the documents change in front of your eyes. The PATCH client is simple thanks to the LWP library. Its main entry point is an exported subroutine named PATCH():
sub PATCH {
require LWP::UserAgent;
@Apache::PATCH::ISA = qw(LWP::UserAgent);
my $ua = __PACKAGE__->new;
my $url;
my $args = @_ ? \@_ : \@ARGV;
while (my $arg = shift @$args) {
$opt_C = shift @$args, next if $arg eq "-C";
$url = $arg;
}
PATCH() starts by creating a new LWP user agent using the subclassing technique
discussed later in the Apache::AdBlocker
module (see Handling Proxy Requests in this chapter). It then recovers the authentication username and password
from the command line by looking for a -C (credentials) switch, which is stored into a package lexical named
my $req = HTTP::Request->new('PATCH' => $url);
my $patch = join '', <STDIN>;
$req->content(\$patch);
$req->header('Content-length' => length $patch);
$req->header('Content-type' => PATCH_TYPE);
my $res = $ua->request($req);
The subroutine now creates a new HTTP::Request object that specifies PATCH as its request method, and sets its content to the diff file read in from STDIN. It also sets the Content-length and Content-type HTTP headers to the length of the diff file and application/diff respectively. Having set up the request, the subroutine sends the request to the remote server by calling the user agent's request() method.
if($res->is_success) {
print $res->content;
}
else {
print $res->as_string;
}
}
If the response indicates success (is_success() returns true) then we print out the text of the server's response. Otherwise the routine prints the error message contained in the response object's as_string() method.
sub get_basic_credentials {
my($self, $realm, $uri) = @_;
return split ':', $opt_C, 2;
}
The get_basic_credentials() method, defined at the bottom of the source listing, is actually an
override of an LWP::UserAgent method. When LWP::UserAgent tries to access a document that is password protected, it invokes this
method to return the username and password required to fetch the resource.
By subclassing LWP::UserAgent into our own package and then defining a get_basic_credentials() method, we're able to provide our parent class with the contents of the To run the client from the command line, invoke it like this:
% perl -MApache::PATCH -e PATCH -- -C username:password \ http://www.modperl.com/index.html < index.html.diff
Hmm... Looks like a new-style context diff to me... The text leading up to this was: -------------------------- |*** index.html.new Mon Aug 24 21:52:29 1998 |--- index.html Mon Aug 24 21:51:06 1998 -------------------------- Patching file /home/httpd/htdocs/index.html using Plan A... Hunk #1 succeeded at 8. done A tiny script named PATCH that uses the module can save some typing:
#!/usr/local/bin/perl
use Apache::PATCH; PATCH;
__END__ Now the command looks like this:
% PATCH -C username:password \ http://www.modperl.com/index.html < index.html.diff
Customizing the Type Checker PhaseFollowing the successful completion of the access control and authentication steps (if configured), Apache tries to determine the MIME type (e.g. image/gif) and encoding type (e.g. x-gzip) of the requested document. The types and encodings are usually determined by filename extensions (the term ``suffix'' is used interchangeably with ``extension'' in the Apache source code and documentation). Table 7.1 lists a few common examples.
MIME types: extension | type -------------------------- .txt | text/plain .html,.htm | text/html .gif | image/gif .jpg,.jpeg | image/jpeg .mpeg,.mpg | video/mpeg .pdf | application/pdf
Encodings: extension | encoding -------------------------- .gz | x-gzip .Z | x-compress By default, Apache's type checker phase is handled by the standard mod_mime module, which combines the information stored in the server's conf/mime.types file with AddType and AddEncoding directives to map file extensions onto MIME types and encodings. Once the document's MIME type is determined, the information is saved in the content_type field of the request record, where it is later used during the response phase to determine which module will be responsible for generating the document content. In general, file types that are determined by the AddType and mime.types mapping will be served from disk. If the optional mod_mmap_static or Apache::Mmap modules are installed, the file may be served straight from shared memory, since both content handlers accept */* in order to handle any document type not specifically requested by another handler. The contents of the request record's content_type field are used to set the default outgoing Content-type header, which the client uses to decide how to render the document. However, as we've seen, content handlers can, and often do, change the content type during the later response phase. In addition to its responsibility for choosing MIME and encoding types for the requested document, the type checking phase handler also performs the crucial task of selecting the content handler for the document. mod_mime looks first for a SetHandler directive in the current directory or location. If one is set, it uses that handler for the requested document. Otherwise it dispatches the request based on the MIME type of the document. This process was described in more detail at the beginning of Chapter 4. Also see Reimplementing mod_mime in Perl, below, where we reproduce all of mod_mime's functionality with a Perl module.
A DBI-Based Type CheckerIn this section, we'll show you a simple type checker handler that determines the MIME type of the document on the basis of a DBI database lookup. Each record of the database table will contain the name of the file, its MIME type, and its encoding.* If no type is registered in the database, we fall through to the default mod_mime handler.
+----------+------------+------------+ | filename | mime_type | encoding | +----------+------------+------------+ | test1 | text/plain | NULL | | test2 | text/html | NULL | | test3 | text/html | x-compress | | test4 | text/html | x-gzip | | test5 | image/gif | NULL | +----------+------------+------------+
Assuming that a hash named
$type = $DB{'test2'}{'mime_type'};
$encoding = $DB{'test2'}{'encoding'};
Listing 7.6 gives the source for Apache::MimeDBI.
package Apache::MimeDBI; # file Apache/MimeDBI.pm use strict; use Apache::Constants qw(:common); use Tie::DBI (); use File::Basename qw(basename); use constant DEFAULT_DSN => 'mysql:test_www'; use constant DEFAULT_LOGIN => ':'; use constant DEFAULT_TABLE => 'doc_types'; use constant DEFAULT_FIELDS => 'filename:mime_type:encoding';
The module starts by pulling in necessary Perl libraries, including
Tie::DBI and the File::Basename filename parser. It also defines a series of default configuration
constants.
sub handler {
my $r = shift;
# get filename
my $file = basename $r->filename;
# get configuration information
my $dsn = $r->dir_config('MIMEDatabase') || DEFAULT_DSN;
my $table = $r->dir_config('MIMETable') || DEFAULT_TABLE;
my($filefield, $mimefield, $encodingfield) =
split ':',$r->dir_config('MIMEFields') || DEFAULT_FIELDS;
my($user, $pass) = split ':', $r->dir_config('MIMELogin') || DEFAULT_LOGIN;
The handler() subroutine begins by shifting the request object off the subroutine call stack and using it to recover the requested document's filename. The directory part of the filename is then stripped away using the basename() routine imported from File::Basename. Next, we fetch the values of our four configuration variables. If any are undefined, we default to the values defined by the previously-declared constants.
tie my %DB, 'Tie::DBI', {
'db' => $dsn, 'table' => $table, 'key' => $filefield,
'user' => $user, 'password' => $pass,
};
my $record;
We now tie a hash named
return DECLINED unless tied %DB and $record = $DB{$file};
The next step is to check the tied hash to see if there is a record
corresponding to the current filename. If there is, we store the record in
a variable named $record. Otherwise, we again return
$r->content_type($record->{$mimefield});
$r->content_encoding($record->{$encodingfield})
if $record->{$encodingfield};
Since the file is listed in the database, we fetch the values of the MIME type and encoding columns and write them into the request record by calling the request object's content_type() and content_encoding() respectively. Since most documents do not have an encoding type, we only call content_encoding() if the column is defined.
return OK; } Our work is done, so we exit the handler subroutine with an OK status code. At the end of this module is a short shell script which you can use to initialize a test database named test_www. It will create the table shown in the example above. To install this module, add a PerlTypeHandler directive like this one to one of the configuration files or a .htaccess file:
<Location /mimedbi> PerlTypeHandler Apache::MimeDBI </Location> If you need to change the name of the database, the login information, or the table structure, be sure to include the appropriate PerlSetVar directives as well. Figure 7.2 shows the automatic listing of a directory under the control of Apache::MimeDBI. The directory contains several files. ``test1'' through ``test5'' are listed in the database with the MIME types and encodings shown in the table above. Their icons reflect the MIME types returned by the handler subroutine. This MIME type will also be passed to the browser when it loads and renders the document. test6.html doesn't have an entry in the database, so it falls through to the standard MIME checking module, which figures out its type through its file extension. test7 has neither an entry in the database nor a recognized file extension, so it is displayed with the ``unknown document'' icon. Without help from Apache::MimeDBI, all the files without extensions would end up as unknown MIME types.
package Apache::MimeDBI;
# file Apache/MimeDBI.pm
use strict;
use Apache::Constants qw(:common);
use Tie::DBI ();
use File::Basename qw(basename);
use constant DEFAULT_DSN => 'mysql:test_www';
use constant DEFAULT_LOGIN => ':';
use constant DEFAULT_TABLE => 'doc_types';
use constant DEFAULT_FIELDS => 'filename:mime_type:encoding';
sub handler {
my $r = shift;
# get filename
my $file = basename $r->filename;
# get configuration information
my $dsn = $r->dir_config('MIMEDatabase') || DEFAULT_DSN;
my $table = $r->dir_config('MIMETable') || DEFAULT_TABLE;
my($filefield, $mimefield, $encodingfield) =
split ':', $r->dir_config('MIMEFields') || DEFAULT_FIELDS;
my($user, $pass) = split ':', $r->dir_config('MIMELogin') || DEFAULT_LOGIN;
# pull information out of the database
tie my %DB, 'Tie::DBI', {
'db' => $dsn, 'table' => $table, 'key' => $filefield,
'user' => $user, 'password' => $pass,
};
my $record;
return DECLINED unless tied %DB and $record = $DB{$file};
# set the content type and encoding
$r->content_type($record->{$mimefield});
$r->content_encoding($record->{$encodingfield})
if $record->{$encodingfield};
return OK;
}
1;
__END__
# Here's a shell script to add the test data
#!/bin/sh
mysql test_www <<END
DROP TABLE doc_types;
CREATE TABLE doc_types (
filename char(127) primary key,
mime_type char(30) not null,
encoding char(30)
);
INSERT into doc_types values ('test1','text/plain',null);
INSERT into doc_types values ('test2','text/html',null);
INSERT into doc_types values ('test3','text/html','x-compress');
INSERT into doc_types values ('test4','text/html','x-gzip');
INSERT into doc_types values ('test5','image/gif',null);
END
Customizing the Fixup PhaseThe fixup phase is sandwiched between the type checking phase and the response phase. It gives modules a last minute chance to add information to the environment or to modify the request record before the content handler is invoked.The standard mod_usertrack module implements the CookieTracking directive in this phase, adding a user-tracking cookie to the outgoing HTTP headers, and recording a copy of the incoming cookie to the notes table for logging purposes.
As an example of a useful Perl-based fixup handler, we'll look at
Apache::HttpEquiv, a module written by Rob Hartill and used here with his permission. The
idea of Apache::HttpEquiv is simple. The module scans the requested HTML file for any For example, if the requested file contains this HTML:
<HTML> <HEAD><TITLE>My Page</TITLE> <META HTTP-EQUIV="Expires" CONTENT="Wed, 31 Jul 1998 16:40:00 GMT"> <META HTTP-EQUIV="Set-Cookie" CONTENT="open=sesame">
The handler will convert the
Expires: Wed, 31 Jul 1998 16:40:00 GMT Set-Cookie: open=sesame
Listing 7.7 gives the succinct code for Apache::HttpEquiv. The
handler() routine begins by testing the current request for suitability. It returns
with a status code of
Next the handler scans through the requested file, line by line, looking
for suitable
Once the file is completely scanned, the subroutine closes and return an To configure Apache::HttpEquiv add the following line to your configuration file:
<Location /httpequiv> PerlFixupHandler Apache::HttpEquiv </Location>
package Apache::HttpEquiv; # file: Apache/HttpEquiv.pm use strict; use Apache::Constants qw(:common);
sub handler {
my $r = shift;
local(*FILE);
return DECLINED if # don't scan the file if.. !$r->is_main # a subrequest || $r->content_type ne "text/html" # it isn't HTML || !open(FILE, $r->filename); # we can't open it
while(<FILE>) {
last if m!<BODY>|</HEAD>!i; # exit early if in BODY
if (m/META HTTP-EQUIV="([^"]+)"\s+CONTENT="([^"]+)"/i) {
$r->header_out($1 => $2);
}
}
close(FILE);
return OK;
}
1;
__END__
The Logging PhaseThe very last phase of the transaction before the cleanup at the end is the logging phase. At this point, the request record contains everything there is to know about the transaction, including the content handler's final status code and the number of bytes transferred from the server to the client.Apache's built-in logging module mod_log_config ordinarily handles this phase by writing a line of summary information to the transfer log. As its name implies this module is highly configurable. You can give it printf()-like format strings to customize the appearance of the transfer log to your requirements, have it open multiple log files, or even have it pipe the log information to an external process for special processing. By handling the logging phase yourself you can perform special processing at the end of each transaction. For example, you can update a database of cumulative hits, bump up a set of hit count files, or notify the owner of a document that his page has been viewed. There are a number of log handlers on CPAN, including Apache::DBILogger, which sends log information to a relational database, and Apache::Traffic, which keeps summaries of bytes transferred on a per-user basis.
Send E-Mail When a Page is HitThe first example of a log handler that we'll show is Apache::LogMail. It sends e-mail to a designated address whenever a particular page is hit, and could be used in low-volume applications such as ISP customers' vanity home pages. A typical configuration directive would look like this:
<Location /~kryan> PerlLogHandler Apache::LogMail PerlSetVar LogMailto [email protected] PerlSetVar LogPattern \.(html|txt)$ </Location> With this configuration in place, hits on pages in the /~kryan directory will generate e-mail messages. The LogMailto Perl configuration variable specifies [email protected] as the lucky recipient of these messages, and LogPattern limits the messages to files that end with .html or .txt (thus eliminating noise from hits on inline images). Listing 7.8 shows the code. After the usual preliminaries, we define the logging phase's handler() routine:
sub handler {
my $r = shift;
my $mailto = $r->dir_config('LogMailto');
return DECLINED unless $mailto;
my $filepattern = $r->dir_config('LogPattern');
return DECLINED if $filepattern
&& $r->filename !~ /$filepattern/;
The subroutine begins by fetching the contents of the LogMailto configuration variable. If none are defined, it declines the transaction. Next it fetches the contents of LogPattern. If it finds one, it compares the requested document's filename to the pattern and again declines the transaction if no match is found.
my $request = $r->the_request;
my $uri = $r->uri;
my $agent = $r->header_in("User-agent");
my $bytes = $r->bytes_sent;
my $remote = $r->get_remote_host;
my $status = $r->status_line;
my $date = localtime;
Now the subroutine gathers up various fields of interest from the request object, including the requested URI, the User-Agent header, the name of the remote host, and the number of bytes sent (method bytes_sent()).
local $ENV{PATH}; #keep -T happy
unless (open MAIL, "|/usr/lib/sendmail -oi -t") {
$r->log_error("Couldn't open mail: $!");
return DECLINED;
}
We open a pipe to the sendmail program* and use it to send a message to the designated user with the information we've gathered. The flags used to open up the sendmail pipe instruct it to take the recipient's address from the header rather than the command line, and prevent it from terminating prematurely if it sees a line consisting of a dot.
print MAIL <<END; To: $mailto From: mod_perl httpd <$from> Subject: Somebody looked at $uri At $date, a user at $remote looked at $uri using the $agent browser. The request was $request, which resulted returned a code of $status. $bytes bytes were transferred. END close MAIL; return OK; }
All text that we print to the The final e-mail message will look something like this:
From: Mod Perl <[email protected]> To: [email protected] Subject: Somebody looked at /~kryan/guestbook.txt Date: Thu, 27 Aug 1998 08:14:23 -0400 At Thu Aug 27 08:14:23 1998, a user at 192.168.2.1 looked at /~kryan/guestbook.txt using the Mozilla/4.04 [en] (X11; I; Linux 2.0.33 i686) browser. The request was GET /~kryan/guestbook.txt HTTP/1.0, which resulted returned a code of 200 OK. 462 bytes were transferred.
package Apache::LogMail;
# File: Apache/LogMail.pm
use strict;
use Apache::Constants qw(:common);
sub handler {
my $r = shift;
my $mailto = $r->dir_config('LogMailto');
return DECLINED unless $mailto;
my $filepattern = $r->dir_config('LogPattern');
return DECLINED if $filepattern
&& $r->filename !~ /$filepattern/;
my $request = $r->the_request;
my $uri = $r->uri;
my $agent = $r->header_in("User-agent");
my $bytes = $r->bytes_sent;
my $remote = $r->get_remote_host;
my $status = $r->status_line;
my $date = localtime;
my $from = $r->server->server_admin || "webmaster";
local $ENV{PATH}; #keep -T happy
unless (open MAIL, "|/usr/lib/sendmail -oi -t") {
$r->log_error("Couldn't open mail: $!");
return DECLINED;
}
print MAIL <<END;
To: $mailto
From: mod_perl httpd <$from>
Subject: Somebody looked at $uri
At $date, a user at $remote looked at
$uri using the $agent browser.
The request was $request,
which resulted returned a code of $status.
$bytes bytes were transferred.
END
close MAIL;
return OK;
}
1;
__END__
A DBI Database LoggerThe second example of a log phase handler is a DBI database logger. The information from the transaction is sent to a relational database using the DBI interface. The record of each transaction is appended to the end of a relational table, which can be queried and summarized in a myriad of ways using SQL.This is a skeletal version of the much more complete Apache::DBILog and Apache::DBILogConfig modules, which you should consult before rolling your own. In preparation to use this module you'll need to set up a database with the appropriate table definition. A suitable MySQL table named access_log is shown here:
+---------+--------------+------+-----+---------------------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------------------+-------+ | when | datetime | | | 0000-00-00 00:00:00 | | | host | char(255) | | | | | | method | char(4) | | | | | | url | char(255) | | | | | | auth | char(50) | YES | | NULL | | | browser | char(50) | YES | | NULL | | | referer | char(255) | YES | | NULL | | | status | int(3) | | | 0 | | | bytes | int(8) | YES | | 0 | | +---------+--------------+------+-----+---------------------+-------+ This table can be created with the following script:
#!/bin/sh mysql -B test_www <<END create table access_log ( when datetime not null, host varchar(255) not null, method varchar(4) not null, url varchar(255) not null, auth varchar(50), browser varchar(50), referer varchar(255), status smallint(3) default 0, bytes int(8) ); END The database must be writable by the Web server, which should be provided with the appropriate username and password to log in. The code (Listing 7.9) is short and very similar to the previous example, so we won't reproduce it inline. We begin by bringing in modules that we need, including DBI and the ht_time() function from Apache::Util. Next we declare some constants defining the database, table and database login information. Since this is just a skeleton of a module, we have hard-coded these values rather than take them from PerlSetVar configuration directives. You can follow the model of Apache::MimeDBI if you wish to make this module more configurable.
The handler() subroutine recovers the request object and uses it to fetch all the
information we're interested in recording, which we store in locals. We
also call ht_time() to produce a nicely-formatted representation of the request_time() in a format that SQL accepts. We connect to the database and create a
statement handle containing a SQL INSERT statement. We invoke the statement
handler's execute() statement to write the information into the database, and return with a
status code of
The only trick to this handler, that we left out of
Apache::LogMail, is the use of the last() to recover the request object. last() returns the final request object in a chain of internal redirects and other
subrequests. Usually there are no subrequests and last() just returns the main (first) request object, in which case, the
package Apache::LogDBI;
# file: Apache/LogDBI.pm
use Apache::Constants qw(:common);
use strict;
use DBI ();
use Apache::Util qw(ht_time);
use constant DSN => 'dbi:mysql:test_www';
use constant DB_TABLE => 'access_log';
use constant DB_AUTH => ':';
sub handler {
my $orig = shift;
my $r = $orig->last;
my $date = ht_time($orig->request_time, '%Y-%m-%d %H:%M:%S', 0);
my $host = $r->get_remote_host;
my $method = $r->method;
my $url = $orig->uri;
my $user = $r->connection->user;
my $referer = $r->header_in('Referer');
my $browser = $r->header_in('User-agent');
my $status = $orig->status;
my $bytes = $r->bytes_sent;
my $dbh = DBI->connect(DSN, split ':', DB_AUTH) || die $DBI::errstr;
my $sth = $dbh->prepare("INSERT INTO ${\DB_TABLE} VALUES(?,?,?,?,?,?,?,?,?)")
|| die $dbh->errstr;
$sth->execute($date,$host,$method,$url,$user,
$browser,$referer,$status,$bytes) || die $dbh->errstr;
return OK;
}
1;
__END__
Having Web transactions logged to a relational database gives you the ability to pose questions of great complexity. Just to give you a taste of what's possible, here are a few useful SQL queries to try:
PerlLogHandler Apache::LogDBI You can place this directive in the main part of the configuration file in order to log all accesses, or place it in a directory section if you're interested in logging a particular section of the site only. An alternative is to install Apache::LogDBI as a cleanup handler, as described in the next section.
Registered CleanupsAlthough the logging phase is the last official phase of the request cycle, there is one last place where modules can do work. This is the cleanup phase, during which any code registered as a cleanup handler is called to perform any per-transaction tidying up that the module may need to do.Cleanup handlers can be installed in either of two ways. They can be installed by calling the request object's register_cleanup() method with a reference to a subroutine or method to invoke, or by using the PerlCleanupHandler directive to register a subroutine from within the server configuration file. Examples:
# within a module file
$r->register_cleanup(sub { warn "server $$ done serving request\n" });
# within a configuration file PerlModule Apache::Guillotine # make sure it's loaded PerlCleanupHandler Apache::Guillotine::mopup()
There is not actually a cleanup phase per se. Instead the C API provides a
callback mechanism for functions that are invoked just before their memory
pool is destroyed. A handful of Apache API methods use this mechanism
underneath for simple but important tasks such as ensuring that files,
directory handles and sockets are closed. In Chapter 10, you will see that
the C version expects a few more arguments, including the There are actually two register_cleanup() methods, one associated with the Apache request object, and the other associated with the Apache::Server object. The difference between the two is that handlers installed with the request object's method will be run when the request is done, while handlers installed with the server object's method will only be run only when the server shuts down or restarts:
$r->register_cleanup(sub { "child $$ served another request" })
Apache->server->register_cleanup(sub { warn "server $$ restarting\n" });
We've already been using register_cleanup() indirectly with the Apache::File tmpfile() method, where it is used to unlink a temporary file at the end of the transaction even if the handler aborts prematurely. Another example can be found in CGI.pm, where a cleanup handler resets that module's package globals to a known state after each transaction. Here's the relevant code fragment:
Apache->request->register_cleanup(\&CGI::_reset_globals); A more subtle use of registered cleanups is to perform delayed processing on requests. For example, certain contributed mod_perl logging modules like Apache::DBILogger and Apache::Traffic take a bit more time to do their work than the standard logging modules do when they append a line of text to a flat file. Although the overhead is small, it does lengthen the amount of time the user has to wait before the browser's progress monitor indicates that the page is fully loaded. In order to squeeze out the last ounce of performance, these modules defer the real work to the cleanup phase. Because cleanups occur after the response is finished, the user will not have to wait for the logging module to complete its work.* To take advantage of delayed processing, we can run the previous section's Apache::LogDBI module during the cleanup phase rather than the log phase. The change is simple. Just replace the PerlLogHandler directive with PerlCleanupHandler:
PerlCleanupHandler Apache::LogDBI
sub handler {
shift->post_connection(\&logger);
}
Cleanup handlers follow the same calling conventions as other handlers. On entry, they receive a reference to an Apache object containing all the accumulated request and response information. They can return a status code if they wish to, but Apache will ignore it. We've finally run out of transaction phases to talk about, so we turn our attention to a more esoteric aspect of Apache, the proxy server API.
Handling Proxy RequestsThe HTTP proxy protocol was originally designed to allow users unfortunate enough to be stuck behind a firewall to access external Web sites. Instead of connecting to the remote server directly, an action forbidden by the firewall, users point their browsers at a proxy server located on the firewall machine itself. The proxy goes out and fetches the requested document from the remote site, and forwards the retrieved document to the user.Nowadays most firewall systems have a simple Web proxy built right in, so there's no need for dedicated proxying servers. However proxy servers are still useful for a variety of purposes. For example, a caching proxy (of which Apache is one example) will store frequently-requested remote documents in a disk directory and return the cached documents directly to the browser instead of fetching them anew. Anonymizing proxies take the outgoing request and strip out all the headers that can be used to identify the user or his browser. By writing Apache API modules that participate in the proxy process, you can achieve your own special processing of proxy requests. The proxy request/response protocol is nearly the same as vanilla HTTP. The major difference is that instead of requesting a server-relative URI in the request line, the client asks for a full URL, complete with scheme and host. In addition, a few optional HTTP headers beginning with Proxy- may be added to the request. For example, a normal (non-proxy) HTTP request sent by a browser might like this:
GET /foo/index.html HTTP/1.0 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Pragma: no-cache Connection: Keep-Alive User-Agent: Mozilla/2.01 (WinNT; I) Host: www.modperl.com:80 In contrast, the corresponding HTTP proxy request will look like this:
GET http://www.modperl.com/foo/index.html HTTP/1.0 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Pragma: no-cache User-Agent: Mozilla/2.01 (WinNT; I) Host: www.modperl.com:80 Proxy-Connection: Keep-Alive Notice the URL in the request line of an HTTP proxy request includes the scheme and hostname. This information enables the proxy server to initiate a connection to the distant server. To generate this type of request, the user must configure his browser so that HTTP and, optionally, FTP requests are proxied to the server. This usually involves setting values in the browser's preference screens. An Apache server will be able to respond to this type of request if it has been compiled with the mod_proxy module. This module is part of the core Apache distribution but is not compiled in by default. You can interact with Apache's proxy mechanism at the translation handler phase. There are two types of interventions you can make. You can take an ordinary (non-proxy) request and change it into one so that it will be handled by Apache's standard proxy module. Or you can take an incoming proxy request and install your own content handler for it so that you can examine and possibly modify the response from the remote server.
Invoking mod_proxy for Non-Proxy RequestsWe'll look first at Apache::PassThru, an example of how to turn an ordinary request into a proxy request.* Because this technique uses Apache's optional mod_proxy module, this module will have to be compiled and installed in order for this example to run on your system.
The configuration for this example uses a PerlSetVar to set a variable named PerlPassThru. A typical entry in the configuration directive will look like this:
PerlTransHandler Apache::PassThru PerlSetVar PerlPassThru '/CPAN/ => http://www.perl.com/,\ /search/ => http://www.altavista.digital.com/' The PerlPassThru variable contains a string representing a series of URI=>proxy pairs, separated by commas. A backslash at the end of a line can be used to split the string over several lines, improving readability (the ability to use backslash as a continuation character is actually an Apache configuration file feature, but not a well-publicized one). In this example, we map the URI /CPAN/ to http://www.perl.com/ and /search/ to http://www.altavista.digital.com/. For the mapping to work correctly, local directory names should end with a slash in the manner shown in the example. The short code for Apache::PassThru is given in Listing 7.10. The handler() subroutine begins by retrieving the request object, and calling its proxyreq() method to determine whether the current request is a proxy request:
sub handler {
my $r = shift;
return DECLINED if $r->proxyreq;
If this is already a proxy request, we don't want to alter it in any way,
so we decline the transaction. Otherwise we retrieve the value of PerlPassThru, split it into its key/value components with a pattern match, and store
the result in a hash named
my $uri = $r->uri;
my %mappings = split /\s*(?:,|=>)\s*/, $r->dir_config('PerlPassThru');
We now loop through each of the local paths, looking for a match with the current request's URI. If a match is found, we perform a string substitution to replace the local path to the corresponding proxy URI. Otherwise we continue to loop:
for my $src (keys %mappings) {
next unless $uri =~ s/^$src/$mappings{$src}/;
$r->proxyreq(1);
$r->uri($uri);
$r->filename("proxy:$uri");
$r->handler('proxy-server');
return OK;
}
If the URI substitution succeeds, there are four steps we need to take to
transform this request into something that mod_proxy will handle. The first two are obvious, but the others are less so. First,
we need to set the proxy request flag to a true value by calling
} return DECLINED; } If we turned the local path into a proxy request, we return OK from the translation handler. Otherwise we returned DECLINED.
package Apache::PassThru; # file: Apache/PassThru.pm; use strict; use Apache::Constants qw(:common);
sub handler {
my $r = shift;
return DECLINED if $r->proxyreq;
my $uri = $r->uri;
my %mappings = split /\s*(?:,|=>)\s*/, $r->dir_config('PerlPassThru');
for my $src (keys %mappings) {
next unless $uri =~ s/^$src/$mappings{$src}/;
$r->proxyreq(1);
$r->uri($uri);
$r->filename("proxy:$uri");
$r->handler('proxy-server');
return OK;
}
return DECLINED;
}
1;
__END__
An Anonymizing ProxyAs public concern about the ability of Web servers to track people's surfing sessions grows, anonymizing proxies are becoming more popular. An anonymizing proxy is similar to an ordinary Web proxy, except that certain HTTP headers that provide identifying information such as the Referer, Cookie, User-Agent and From fields are quietly stripped from the request before forwarding it on to the remote server. Not only is this identifying information removed, but the identity of the requesting host is obscured. The remote server knows only the hostname and IP address of the proxy machine, not the identity of the machine the user is browsing from.You can write a simple anonymizing proxy in the Apache Perl API in all of 18 lines (including comments). The source code listing is shown in Listing 7.11. Like the previous example, it uses Apache's mod_proxy, so that module must be installed before this example will run correctly.
The module defines a package global named If proxyreq() returns true we now know that we are in the midst of a proxy request. We loop through each of the fields to be stripped and delete them from the incoming headers table by using the request object's header_in() method to set the field to undef. We then return OK to signal Apache to continue to the request processing. That's all there is to it. To activate the anonymizing proxy, install it as a URI translation handler as before:
PerlTransHandler Apache::AnonProxy Another alternative that works just as well is to call the module during the later header parser parsing phase (see the discussion of this phase below). In some ways this makes more sense because we aren't doing any actual URI translation, but we are modifying the HTTP header. Here is the appropriate directive:
PerlHeaderParserHandler Apache::AnonProxy The drawback to using PerlHeaderParserHandler like this is that, unlike PerlTransHandler, the directive is allowed in directory configuration sections and .htaccess files. But directory configuration sections are irrelevant in proxy requests, so the directive will silently fail if placed in one of these sections. The directive should go in the main part of the one of the configuration files, or in a virtual host section.
package Apache::AnonProxy; # file: Apache/AnonProxy.pm use strict; use Apache::Constants qw(:common);
my @Remove = qw(user-agent cookie from referer);
sub handler {
my $r = shift;
return DECLINED unless $r->proxyreq;
foreach (@Remove) {
$r->header_in($_ => undef);
}
return OK;
}
1; __END__ In order to test that this handler was actually working, we set up a test Apache server as the target of the proxy requests and added the following entry to its configuration file:
CustomLog logs/nosy_log "%h %{Referer}i %{User-Agent}i %{Cookie}i %U"
This created a ``nosy'' log that contains entries for the referrer, user agent and cookie fields. Before installing the anonymous proxy module, entries in this log looked like this (the lines have been wrapped to fit on the page):
192.168.2.5 http://prego/ Mozilla/4.04 [en] (X11; I; Linux 2.0.33 i686) - /tkdocs/tk_toc.ht 192.168.2.5 http://prego/ Mozilla/4.04 [en] (X11; I; Linux 2.0.33 i686) POMIS=10074 /perl/hangman1.pl In contrast, after installing the anonymizing proxy module, all the identifying information was stripped out, leaving only the IP address of the proxy machine:
192.168.2.5 - - - /perl/hangman1.pl 192.168.2.5 - - - /icons/hangman/h0.gif 192.168.2.5 - - - /cgi-bin/info2www
Handling the Proxy Process OurselvesAs long as you only need to monitor or modify the request half of a proxy transaction, you can use Apache's mod_proxy module directly as we did in the previous two examples. However, if you also want to intercept the response so as to modify the information returned from the remote server, then you'll need to handle the proxy request on your own.In this section we present Apache::AdBlocker. This module replaces Apache's mod_proxy with a specialized proxy that filters the content of certain URLs. Specifically, it looks for URLs that are likely to be banner advertisements and replaces their content with a transparent GIF image that says ``Blocked Ad''. This can be used to ``lower the volume'' of commercial sites by removing distracting animated GIFs and brightly colored banners. Figure 7.3 shows what the AltaVista search site looks like when fetched through the Apache::AdBlocker proxy.
Later on, when its content handler is called the module uses the Perl LWP library to fetch the remote document. If the document does not appear to be a banner ad, the content handler forwards it on to the waiting client. Otherwise the handler does a little switcharoo, replacing the advertisement with a custom GIF image of exactly the same size and shape as the ad. This bit of legerdemain is completely invisible to the browser, which goes ahead and renders the image as if it were the original banner ad. In addition to the LWP library, this module requires the GD and Image::Size libraries for creating and manipulating images. They are available on CPAN if you do not already have them installed. Turning to the code, after the familiar preamble we create a new LWP::UserAgent object that we will use to make all our requests for documents from remote servers.
@ISA = qw(LWP::UserAgent); $VERSION = '1.00'; my $UA = __PACKAGE__->new; $UA->agent(join "/", __PACKAGE__, $VERSION);
sub redirect_ok {0}
We subclass LWP::UserAgent, using the We now create a new instance of the LWP::UserAgent subclass, using the special token __PACKAGE__ which evaluates at compile time to the name of the current package. In this case, __PACKAGE__->new is equivalent to Apache::AdBlocker->new (or new Apache::AdBlocker if you prefer Smalltalk syntax). Immediately afterward we call the object's agent() method with a string composed of the package name and version number. This is the calling card that LWP sends to the remote hosts' Web servers as the HTTP User-Agent field. The method we use for constructing the User-Agent field creates the string ``Apache::AdBlocker/1.00''.
my $Ad = join "|", qw{ads? advertisements? banners? adv promotions?};
The last initialization step is to define a package global named
sub handler {
my $r = shift;
return DECLINED unless $r->proxyreq;
$r->handler("perl-script"); #ok, let's do it
$r->push_handlers(PerlHandler => \&proxy_handler);
return OK;
}
The next part of the module is the definition of the handler() subroutine, which in this case will be run during the URI translation phase. It simply checks whether the current transaction is a proxy requests and declines the transaction if not. Otherwise, it calls the request object's handler() method to set the content handler to ``perl-script'', and calls push_handlers() to make the module's proxy_handler() subroutine the callback for the response phase of the transaction. handler() then returns OK to flag that it has handled the URI translation phase. Most of the work is done in proxy_handler(). Its job is to use LWP's object-oriented methods to create an HTTP::Request object. The HTTP::Request is then forwarded to the remote host by the LWP::UserAgent, returning an HTTP::Respons. The response must then be forwarded on to the waiting browser, possibly after replacing the content. The only subtlety here is the need to copy the request headers from the incoming Apache request's headers_in() table to the HTTP::Request, and, in turn, to copy the response headers from the HTTP::Response into the Apache request headers_out() table. If this copying back and forth isn't performed, then documents that rely on the exact values of certain HTTP fields, such as CGI scripts, will fail to work correctly across the proxy.
sub proxy_handler {
my $r = shift;
my $request = HTTP::Request->new($r->method, $r->uri);
proxy_handler() starts by recovering the Apache request object. It then uses the request object's method() and uri() methods to fetch the request method and the URI. These are used to create and initialize a new HTTP::Request. We now feed the incoming header fields from the Apache request object into the corresponding fields in the outgoing HTTP::Request:
$r->headers_in->do(sub {
$request->header(@_);
});
We use a little trick to accomplish the copy. The headers_in() method, as opposed to the header_in() method that we have seen before, returns an instance of the Apache::Table class. This class, described in more detail in the next chapter (see The Apache::Table Class), implements methods for manipulating Apache's various table-like structures, including the incoming and outgoing HTTP header fields. One of these methods is do(), which when passed a CODE reference, invokes the code once for each header field, passing the routine the header's name and value each time. In this case, we call do() with an anonymous subroutine that passes the header keys and values on to the HTTP::Request object's header() method. It is important to use headers->do() here rather than copying the headers into a hash because certain headers, particularly Cookie, can be multivalued.
# copy POST data, if any
if($r->method eq 'POST') {
my $len = $r->header_in('Content-length');
my $buf;
$r->read($buf, $len);
$request->content($buf);
}
The next block of code checks whether the request method is POST. If so, we must copy the POSTed data from the incoming request to the HTTP::Request object. We do this by calling the request object's read() method to read the POST data into a temporary buffer. The data is then copied into the HTTP::Request by calling its content() method. Request methods other than POST may include a request body, but this example does not cope with these rare cases. The HTTP::Request object is now complete, so we can actually issue the request:
my $response = $UA->request($request);
We pass the HTTP::Request object to the user agent's request()
method. After a brief delay for the network fetch, the call returns an HTTP::Response object, which we copy into a variable named
$r->content_type($response->header('Content-type'));
$r->status($response->code);
$r->status_line(join " ", $response->code, $response->message);
Now the process of copying the headers is reversed. Every header in the LWP HTTP::Response object must be copied to the Apache request object. First we handle a few special cases. We call the HTTP::Response object's header() method to fetch the content type of the returned document and immediately pass the result to the Apache request object's content_type() method. Next, we set the numeric HTTP status code and the human-readable HTTP status line. We call the HTTP::Response object's code() and message() methods to return the numeric code and human readable messages respectively, and copy them to the Apache request object, using the status() and status_line() methods to set the values. When the special case headers are done, we copy all the other header fields, using the HTTP::Response object's scan() method:
$response->scan(sub {
$r->header_out(@_);
});
scan() is similar to the Apache::Table do() method: it loops through each of the header fields, invoking an anonymous callback routine for each one. The callback sets the corresponding field in the Apache request object using the header_out() method.
if ($r->header_only) {
$r->send_http_header();
return OK;
}
The outgoing header is complete at this point, so we check whether the current transaction is a HEAD request. If so, we emit the HTTP header and exit with an OK status code.
my $content = \$response->content;
if($r->content_type =~ /^image/ and $r->uri =~ /\b($Ad)\b/i) {
block_ad($content);
$r->content_type("image/gif");
}
Otherwise, the time has come to deal with potential banner ads. To identify
likely ads, we require that the document be an image and that its URI
satisfy the regular expression match defined at the top of the module. We
retrieve the document contents by calling the
HTTP::Response object's content() method,* and store a reference to the contents in a local variable named
$r->content_type('text/html') unless $$content;
$r->send_http_header;
$r->print($$content || $response->error_as_HTML);
We send the HTTP header, then print the document contents. Notice that the document content may be empty, which can happen when LWP connects to a server that is down or busy. In this case, instead of printing an empty document, we return the nicely-formatted error message returned by the HTTP::Response object's error_as_HTML() method.
return OK; } Our work is done, we return an OK status code.
sub block_ad {
my $data = shift;
my($x, $y) = imgsize($data);
my $im = GD::Image->new($x,$y);
To get the width and height of the image we call imgsize(), a function imported from the Image::Size module. imgsize()
recognizes most Web image formats, including GIF, JPEG, XBM and PNG. Using
these values, we create a new blank GD::Image object and store it in a variable named
my $white = $im->colorAllocate(255,255,255); my $black = $im->colorAllocate(0,0,0); my $red = $im->colorAllocate(255,0,0); We call the image object's colorAllocate() method three times to allocate color table entries for white, black and red. Then we declare that the white color is transparent, using the transparent() method.
$im->transparent($white); $im->string(GD::gdLargeFont(),5,5,"Blocked Ad",$red); $im->rectangle(0,0,$x-1,$y-1,$black); $$data = $im->gif; }
The routine calls the string() method to draw the message starting at coordinates (5,5), and finally
frames the whole image with a black rectangle. The custom image is now
converted into GIF format with the
gif() method, and copied into Activating this module is just a matter of adding the following line to one of the configuration files:
PerlTransHandler Apache::AdBlocker Users who wish to make use of this filtering service should configure their browsers to proxy their requests through your server.
package Apache::AdBlocker; # file: Apache/AdBlocker.pm use strict; use vars qw(@ISA $VERSION); use Apache::Constants qw(:common); use GD (); use Image::Size qw(imgsize); use LWP::UserAgent (); @ISA = qw(LWP::UserAgent); $VERSION = '1.00'; my $UA = __PACKAGE__->new; $UA->agent(join "/", __PACKAGE__, $VERSION);
sub redirect_ok {0}
my $Ad = join "|", qw{ads? advertisements? banners? adv promotions?};
sub handler {
my $r = shift;
return DECLINED unless $r->proxyreq;
$r->handler("perl-script"); #ok, let's do it
$r->push_handlers(PerlHandler => \&proxy_handler);
return OK;
}
sub proxy_handler {
my $r = shift;
my $request = HTTP::Request->new($r->method, $r->uri);
$r->headers_in->do(sub {
$request->header(@_);
});
# copy POST data, if any
if($r->method eq 'POST') {
my $len = $r->header_in('Content-length');
my $buf;
$r->read($buf, $len);
$request->content($buf);
}
my $response = $UA->request($request);
$r->content_type($response->header('Content-type'));
#feed response back into our request_rec*
$r->status($response->code);
$r->status_line(join " ", $response->code, $response->message);
$response->scan(sub {
$r->header_out(@_);
});
if ($r->header_only) {
$r->send_http_header();
return OK;
}
my $content = \$response->content;
if($r->content_type =~ /^image/ and $r->uri =~ /\b($Ad)\b/i) {
block_ad($content);
$r->content_type("image/gif");
}
$r->content_type('text/html') unless $$content;
$r->send_http_header;
$r->print($$content || $response->error_as_HTML);
return OK;
}
sub block_ad {
my $data = shift;
my($x, $y) = imgsize($data);
my $im = GD::Image->new($x,$y);
my $white = $im->colorAllocate(255,255,255);
my $black = $im->colorAllocate(0,0,0);
my $red = $im->colorAllocate(255,0,0);
$im->transparent($white);
$im->string(GD::gdLargeFont(),5,5,"Blocked Ad",$red);
$im->rectangle(0,0,$x-1,$y-1,$black);
$$data = $im->gif;
}
1;
__END__
Perl Server-Side IncludesAnother feature of mod_perl is that it integrates with the Apache mod_include server-side include system. Provided that mod_perl was built with thePERL_SSI option (or with the recommended setting of EVERYTHING=1), the Perl API adds a new #perl element to the standard mod_include server-side include system, allowing server-side includes to call Perl
subroutines directly.
The syntax for calling Perl from SSI documents looks like this:
<!--#perl sub="subroutine" args="arguments"--> The tag looks like other server-side include tags but contains the embedded element #perl. The #perl element recognizes two attributes, sub and args. The required sub attribute specifies the subroutine to be invoked. This attribute must occur once only in the tag. It can be the name of any subroutine already loaded into the server (with a PerlModule directive, for instance), or an anonymous subroutine created on the fly. When this subroutine is invoked, it is passed a blessed Apache request object just as if it were a handler for one of the request phases. Any text that the subroutine prints will appear on the HTML page. The optional args attribute can occur once or several times in the tag. If present, args attributes specify additional arguments to be passed to the subroutine. They will be presented to the subroutine in the same order in which they occur in the tag. Listing 7.18 shows a simple server-side include system that uses #perl elements. It has two Perl includes. The simpler of the two is just a call to a routine named MySSI::remote_host(). When executed, it calls the request object's get_remote_host() method to fetch the DNS name of the remote host machine:
<!--#perl sub="MySSI::remote_host" --> MySSI::remote_host() must be preloaded in order for this include to succeed. One way to do this is inside the Perl startup file. Alternatively, it could be defined in a module named MySSI.pm and loaded with the directive PerlModule MySSI. In either case, the definition of remote_host() looks like this:
package MySSI;
sub remote_host {
my $r = shift;
print $r->get_remote_host;
}
We could also have defined the routine to call the request object's print() method, as in $r->print($r->get_remote_host). It's your call. The more complex of the two includes defined in this example calls a Perl subroutine that it creates on the fly. It looks like this:
<!--#perl arg="Hello" arg="SSI" arg="World"
sub="sub {
my($r, @args) = @_;
print qq(@args);
}"
-->
In this case the sub attribute points to an anonymous subroutine defined using the sub { } notation. This subroutine retrieves the request object and a list of
arguments, which it simply prints out. Because double quotes are already
used to surround the attribute, we use Perl's This tag also has three arg attributes, which are passed, in order of appearance, to the subroutine. In order to try this example out, you'll have to have server-side includes activated. This can be done by uncommenting the following two lines in the standard srm.conf server configuration file:
AddType text/html .shtml AddHandler server-parsed .shtml You'll also have to activate the Includes option in the directory in which the document is located. The final result is shown in Figure 7.4.
|
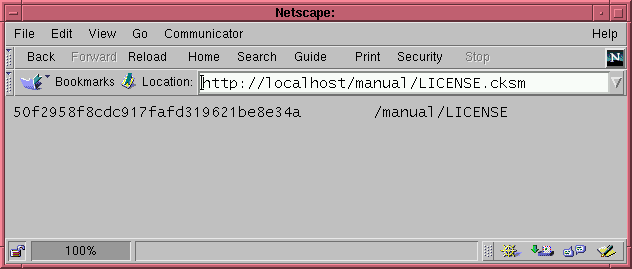
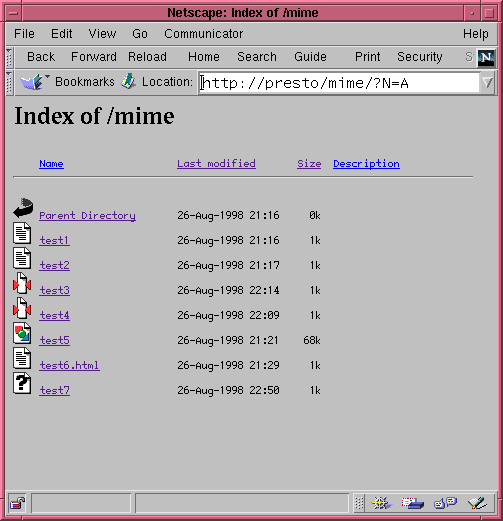
|
|